Versões: Parquet 1.9.0
P>Precisamos de descobrir diferentes métodos de codificação disponíveis no Apache Parquet. Mas a codificação não é a única técnica que ajuda a reduzir o tamanho dos ficheiros. A outra, muito semelhante, é a compressão.
Este post dá uma visão sobre a compressão fornecida pelo Apache Parquet. Contudo, a primeira parte recorda o básico e concentra-se na compressão como um processo independente de qualquer estrutura. Apenas a segunda secção lista e explica os codecs de compressão disponíveis em Parquet. A última secção mostra alguns testes de compressão.
Definição de compressão
Compressão de dados é uma técnica cujo objectivo principal é a redução do tamanho lógico do ficheiro. Assim, o ficheiro reduzido deve ter menos lugar no disco e ser transferido mais rapidamente através da rede. Muito frequentemente a compressão funciona de forma semelhante à codificação. Identifica padrões repetitivos e substitui-os por representações mais compactas.
A diferença entre a codificação e a compressão é subtil. A codificação altera a representação dos dados. Por exemplo, pode representar a palavra “abc” como “11” e muitas vezes pode ser baseada nos mesmos princípios que a compressão. Um exemplo disso é a Codificação em Comprimento de Execução que substitui símbolos repetidos (por exemplo “aaa”) por uma forma mais curta (“3a”). No outro lado, a compressão trata de toda a informação e tira partido da redundância de dados para reduzir o tamanho total. Por exemplo, pode remover as partes de informação que são inúteis (por exemplo, padrões repetidos ou partes de informação sem significado para o receptor).
Codecs de compressão em Parquet
A compressão em Parquet é feita por coluna. Excepto a representação não comprimida, o Apache Parquet vem com 3 codecs de compressão:
- gzip – método de compressão sem perdas bastante popular baseado no algoritmo DEFLATE sendo uma combinação de codificação Huffman e LZ77.
A codificação Huffman é uma técnica de comprimento variável que atribui códigos mais pequenos para os caracteres mais frequentemente utilizados. Por exemplo, se quisermos codificar a palavra “aaaaabbbc” com 2 bits, usaríamos 9*2 = 18 bits. No outro lado, a codificação desta sequência de caracteres com codificação Huffman poderia reduzir o número de bits para 5+3*2+2 = 13 bits onde o carácter mais frequente “a” é codificado como 0 e dois outros em 2 bits habituais. Era uma explicação simples. Mais exactamente, a codificação Huffman funciona através da combinação de árvores com nós representando caracteres de valor codificado. Cada nó representa um carácter e é rotulado com o peso do carácter (= o número de ocorrências). O algoritmo começa com árvores de 1 nó que são combinadas passo a passo até haver apenas 1 árvore. O passo da fusão consiste em escolher 2 árvores com o menor peso e combiná-las em conjunto. No final, a codificação é resolvida através da definição da regra de codificação. Por exemplo, a regra de codificação pode dizer que todos os valores à esquerda são codificados com 1 e os da direita com 0. Este algoritmo é apresentado na imagem abaixo: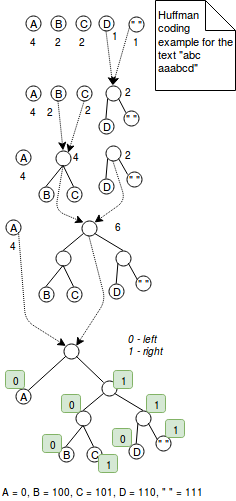 br> No outro lado, LZ77 representa informação repetida em trigémeos mais concisos de (distância, comprimento). Por exemplo, se codificarmos o texto “ABAC” com LZ77, ele será representado como “AB(2,1)C”. A imagem abaixo explica melhor os passos deste método:
br> No outro lado, LZ77 representa informação repetida em trigémeos mais concisos de (distância, comprimento). Por exemplo, se codificarmos o texto “ABAC” com LZ77, ele será representado como “AB(2,1)C”. A imagem abaixo explica melhor os passos deste método: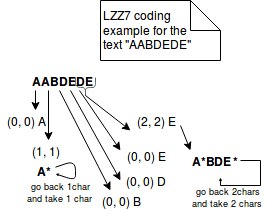
- Snappy – Snappy é um método de compressão de fonte aberta pelo Google, orientado por bytes (bytes inteiros são emitidos ou consumidos a partir de um fluxo). O formato comprimido começa com um campo que indica o comprimento dos dados não comprimidos. Mais tarde, os dados comprimidos são representados ou como literais ou como cópias. Ambas estas representações estão incluídas numa estrutura chamada tag byte. Os 2 bytes baixos desta estrutura indicam a representação utilizada (00 para os literais, 01, 10, 11 para as cópias).
Literal é usado para representar os dados que não podem ser comprimidos. Tem um conceito de comprimento que pode ser armazenado em 2 locais diferentes. Para os literais até 60 bytes, o comprimento é armazenado directamente no byte da etiqueta. Para os literais maiores, o comprimento é armazenado directamente após o byte da etiqueta. Neste caso, o byte da etiqueta contém apenas a informação sobre quantos lugares são ocupados pelo comprimento.
O segundo tipo de representação é chamado cópia. Utiliza um conceito semelhante à codificação LZ77, uma vez que representa dados repetidos em tuplos de (offset, comprimento). Dependendo do comprimento do tuple, podemos distinguir 3 tipos diferentes de cópias:- A cópia com offset de 1 byte codifica os comprimentos entre 4 e 11 bytes. No byte da tag é prefixado com 01 no byte da tag.
- Para a cópia com desvio de 2 bytes, os comprimentos entre 1 e 64 bytes são prefixados com 10 no byte da tag. A informação com offset é armazenada em 2 bytes seguindo o byte da tag como um int.
- A cópia com offset de 4 bytes é representada como 11 no byte da tag. Tem características semelhantes às da cópia anterior. A única diferença é o armazenamento offset que é 32-bit integer.
No entanto, Snappy não é uma codificação puramente LZ77. É mais ao estilo LZ. LZ77 consiste em 2 partes: algoritmo de correspondência que reconhece as repetições e a codificação. Snappy salta a última parte porque usa formato de embalagem fixo e afinado à mão de literais e cópias.
- LZO – método de compressão baseado em dicionário e sem perdas. Favorece a velocidade de compressão em relação à taxa de compressão. O LZO pertence à família das codificações LZ, porque é a variação do LZ77. A diferença é que é optimizado para tirar partido do facto de os computadores de hoje em dia serem optimizados para realizar operações inteiras. Traz tabelas de pesquisa de hash tão rápidas e fichas de saída melhor optimizadas. Os dados que não podem ser comprimidos são copiados de forma não comprimida para o fluxo de saída numa base de palavras de 32 bits.
Não semelhante a 2 métodos de compressão anteriores, a compressão LZO necessita de algum trabalho adicional. Uma biblioteca LZO nativa deve ser instalada separadamente e algumas soluções foram dadas no StackOverflow: Hadoop-LZO estranha biblioteca nativa de LZO não disponível erro ou Classe com.hadoop.compression.lzo.LzoCodec não encontrada para Spark no CDH 5?.
Exemplos de compressão Parquet
Em testes abaixo, devido à complexidade da instalação LZO, apenas são apresentados os codecs gzip e Snappy:
private static final CodecFactory CODEC_FACTORY = new CodecFactory(new Configuration(), 1024);private static final CodecFactory.BytesCompressor GZIP_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.GZIP);private static final CodecFactory.BytesCompressor SNAPPY_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.SNAPPY);private static final BytesInput BIG_INPUT_INTS;static { List<BytesInput> first4000Numbers = IntStream.range(1, 4000).boxed().map(number -> BytesInput.fromInt(number)).collect(Collectors.toList()); BIG_INPUT_INTS = BytesInput.concat(first4000Numbers);}private static final BytesInput SMALL_INPUT_STRING = BytesInput.concat( BytesInput.from(getUtf8("test")), BytesInput.from(getUtf8("test1")), BytesInput.from(getUtf8("test2")), BytesInput.from(getUtf8("test3")), BytesInput.from(getUtf8("test4")));private static final BytesInput INPUT_DATA_STRING;private static final BytesInput INPUT_DATA_STRING_DISTINCT_WORDS;static { URL url = Resources.getResource("lorem_ipsum.txt"); try { String text = Resources.toString(url, Charset.forName("UTF-8")); INPUT_DATA_STRING = BytesInput.from(getUtf8(text)); String textWithDistinctWords = Stream.of(text.split(" ")).distinct().collect(Collectors.joining(", ")); INPUT_DATA_STRING_DISTINCT_WORDS = BytesInput.from(getUtf8(textWithDistinctWords)); } catch (IOException e) { throw new RuntimeException(e); }}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(SMALL_INPUT_STRING); // Compressed size is greater because GZIP adds some additional compression metadata as, header // It can be seen in java.util.zip.GZIPOutputStream.writeHeader() System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(BIG_INPUT_INTS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(SMALL_INPUT_STRING); // For snappy the difference is much less smaller than in the case of Gzip (1 byte) // The difference comes from the fact that Snappy stores the length of compressed output after // the compressed values // You can see that in the Snappy implementation C++ header file: // https://github.com/google/snappy/blob/32d6d7d8a2ef328a2ee1dd40f072e21f4983ebda/snappy.h#L111 System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(BIG_INPUT_INTS); // Snappy is only slightly different than the plain encoding (1 byte less) System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_fail_compress_with_lzo_when_the_native_library_is_not_loaded() throws IOException { assertThatExceptionOfType(RuntimeException.class).isThrownBy(() -> CODEC_FACTORY.getCompressor(CompressionCodecName.LZO)) .withMessageContaining("native-lzo library not available");}private static final byte getUtf8(String text) { try { return text.getBytes("UTF-8"); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e); }}
A compressão é uma das armas de Parquet para a batalha contra o armazenamento ineficiente. É complementar aos métodos de codificação já explicados e também pode ser aplicada a nível de coluna. Isso traz a possibilidade de utilizar diferentes métodos de compressão, de acordo com os dados contidos. Apache Parquet fornece 3 codecs de compressão detalhados na 2ª secção: gzip, Snappy e LZO. Dois primeiros são incluídos nativamente, enquanto o último requer alguma configuração adicional. Como mostrado na secção final, a compressão nem sempre é positiva. Por vezes, os dados comprimidos ocupam mais lugar do que os não comprimidos. Explicaríamos isso por uma sobrecarga extra trazida pela codificação de informação.
TAGS: #Algoritmos de compressão