Versioni: Parquet 1.9.0
L’ultima volta abbiamo scoperto diversi metodi di codifica disponibili in Apache Parquet. Ma la codifica non è l’unica tecnica che aiuta a ridurre la dimensione dei file. L’altra, molto simile, è la compressione.
Questo post dà una visione della compressione fornita da Apache Parquet. Tuttavia la prima parte ricorda le basi e si concentra sulla compressione come un processo indipendente da qualsiasi framework. Solo la seconda sezione elenca e spiega i codec di compressione disponibili in Parquet. L’ultima sezione mostra alcuni test di compressione.
Definizione di compressione
La compressione dei dati è una tecnica il cui scopo principale è la riduzione della dimensione logica del file. Così il file ridotto dovrebbe occupare meno posto sul disco ed essere trasferito più velocemente sulla rete. Molto spesso la compressione funziona in modo simile alla codifica. Identifica i modelli ripetitivi e li sostituisce con rappresentazioni più compatte.
La differenza tra codifica e compressione è sottile. La codifica cambia la rappresentazione dei dati. Per esempio può rappresentare la parola “abc” come “11” e spesso può essere basata sugli stessi principi della compressione. Un esempio è il Run-Length Encoding che sostituisce i simboli ripetuti (per esempio “aaa”) con una forma più breve (“3a”). Dall’altro lato, la compressione si occupa dell’intera informazione e sfrutta la ridondanza dei dati per ridurre la dimensione totale. Per esempio, può rimuovere le parti di informazione che sono inutili (per esempio schemi ripetuti o pezzi di informazione senza senso per il ricevitore).
Codici di compressione in Parquet
La compressione in Parquet è fatta per colonna. A parte la rappresentazione non compressa, Apache Parquet è dotato di 3 codec di compressione:
- gzip – metodo di compressione lossless piuttosto popolare basato sull’algoritmo DEFLATE che è una combinazione di codifica Huffman e LZ77.
La codifica Huffman è una tecnica a lunghezza variabile che assegna codici più piccoli per i caratteri più frequentemente utilizzati. Per esempio, se vogliamo codificare la parola “aaaaabbbc” con 2 bit, useremo 9*2 = 18 bit. Dall’altra parte, codificando questa sequenza di caratteri con la codifica Huffman potremmo ridurre il numero di bit a 5+3*2+2 = 13 bit dove il carattere più frequente “a” è codificato come 0 e gli altri due con i soliti 2 bit. Era una spiegazione semplice. Più esattamente la codifica Huffman funziona combinando alberi con nodi che rappresentano i caratteri del valore codificato. Ogni nodo rappresenta un carattere ed è etichettato con il peso del carattere (= il numero di occorrenze). L’algoritmo inizia con alberi a 1 nodo che vengono combinati passo dopo passo fino ad avere un solo albero. Il passo di fusione consiste nello scegliere 2 alberi con i pesi minori e combinarli insieme. Alla fine la codifica viene risolta definendo una regola di codifica. Per esempio la regola di codifica può dire che tutti i valori a sinistra sono codificati con 1 e quelli a destra con 0. Questo algoritmo è presentato nell’immagine seguente: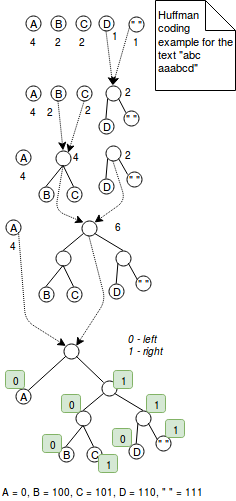
Nell’altro lato, LZ77 rappresenta l’informazione ripetuta in terzine più concise di (distanza, lunghezza). Per esempio, se codifichiamo il testo “ABAC” con LZ77, sarà rappresentato come “AB(2,1)C”. L’immagine qui sotto spiega meglio i passi di questo metodo: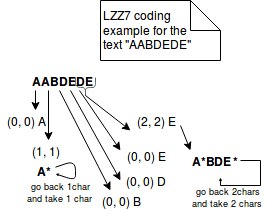
- Snappy – Snappy è un metodo di compressione open-sourced di Google, orientato al byte (byte interi sono emessi o consumati da un flusso). Il formato compresso inizia con un campo che indica la lunghezza dei dati non compressi. Successivamente, i dati compressi sono rappresentati come letterali o come copie. Entrambe queste rappresentazioni sono incluse in una struttura chiamata tag byte. I 2 byte bassi di questa struttura indicano la rappresentazione usata (00 per i letterali, 01, 10, 11 per le copie).
Il letterale è usato per rappresentare i dati che non possono essere compressi. Ha un concetto di lunghezza che può essere memorizzato in 2 posti diversi. Per i letterali fino a 60 byte, la lunghezza è memorizzata direttamente nel byte del tag. Per i letterali più grandi, la lunghezza è memorizzata direttamente dopo il tag byte. In questo caso il tag byte contiene solo l’informazione su quanti posti sono occupati dalla lunghezza.
Il secondo tipo di rappresentazione è chiamato copia. Usa un concetto simile alla codifica LZ77 poiché rappresenta i dati ripetuti in tuple di (offset, lunghezza). A seconda della lunghezza della tupla, possiamo distinguere 3 diversi tipi di copie:- La copia con offset di 1 byte codifica le lunghezze tra 4 e 11 byte. Nel byte tag è prefissato con 01.
- Per la copia con offset a 2 byte le lunghezze tra 1 e 64 byte sono prefissate con 10 nel byte tag. L’informazione di offset è memorizzata in 2 byte dopo il byte tag come un int a 16 bit little-endian.
- La copia con offset a 4 byte è rappresentata come 11 nel byte tag. Ha caratteristiche simili alla copia precedente. L’unica differenza è la memorizzazione dell’offset che è un intero a 32 bit.
Tuttavia, Snappy non è una codifica puramente LZ77. È più simile allo stile LZ. LZ77 consiste in 2 parti: algoritmo di corrispondenza che riconosce le ripetizioni e codifica. Snappy salta l’ultima parte perché usa un formato di impacchettamento fisso e sintonizzato a mano di letterali e copie.
- LZO – metodo di compressione basato sul dizionario e senza perdite. Favorisce la velocità di compressione rispetto al rapporto di compressione. LZO appartiene alla famiglia delle codifiche LZ perché è la variazione di LZ77. La differenza è che è ottimizzata per sfruttare il fatto che i computer di oggi sono ottimizzati per eseguire operazioni intere. Porta così tabelle di hash lookup veloci e token di output meglio ottimizzati. I dati che non possono essere compressi sono copiati in forma non compressa nel flusso di uscita su una base di parola lunga a 32 bit.
A differenza dei 2 metodi di compressione precedenti, la compressione LZO richiede un po’ di lavoro aggiuntivo. Una libreria LZO nativa deve essere installata separatamente e alcune soluzioni sono state date su StackOverflow: Hadoop-LZO strano errore libreria nativa-lzo non disponibile o Classe com.hadoop.compression.lzo.LzoCodec non trovata per Spark su CDH 5?
Esempi di compressione Parquet
Nei test che seguono, a causa della complessità dell’installazione di LZO, vengono presentati solo i codec gzip e Snappy:
private static final CodecFactory CODEC_FACTORY = new CodecFactory(new Configuration(), 1024);private static final CodecFactory.BytesCompressor GZIP_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.GZIP);private static final CodecFactory.BytesCompressor SNAPPY_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.SNAPPY);private static final BytesInput BIG_INPUT_INTS;static { List<BytesInput> first4000Numbers = IntStream.range(1, 4000).boxed().map(number -> BytesInput.fromInt(number)).collect(Collectors.toList()); BIG_INPUT_INTS = BytesInput.concat(first4000Numbers);}private static final BytesInput SMALL_INPUT_STRING = BytesInput.concat( BytesInput.from(getUtf8("test")), BytesInput.from(getUtf8("test1")), BytesInput.from(getUtf8("test2")), BytesInput.from(getUtf8("test3")), BytesInput.from(getUtf8("test4")));private static final BytesInput INPUT_DATA_STRING;private static final BytesInput INPUT_DATA_STRING_DISTINCT_WORDS;static { URL url = Resources.getResource("lorem_ipsum.txt"); try { String text = Resources.toString(url, Charset.forName("UTF-8")); INPUT_DATA_STRING = BytesInput.from(getUtf8(text)); String textWithDistinctWords = Stream.of(text.split(" ")).distinct().collect(Collectors.joining(", ")); INPUT_DATA_STRING_DISTINCT_WORDS = BytesInput.from(getUtf8(textWithDistinctWords)); } catch (IOException e) { throw new RuntimeException(e); }}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(SMALL_INPUT_STRING); // Compressed size is greater because GZIP adds some additional compression metadata as, header // It can be seen in java.util.zip.GZIPOutputStream.writeHeader() System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(BIG_INPUT_INTS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(SMALL_INPUT_STRING); // For snappy the difference is much less smaller than in the case of Gzip (1 byte) // The difference comes from the fact that Snappy stores the length of compressed output after // the compressed values // You can see that in the Snappy implementation C++ header file: // https://github.com/google/snappy/blob/32d6d7d8a2ef328a2ee1dd40f072e21f4983ebda/snappy.h#L111 System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(BIG_INPUT_INTS); // Snappy is only slightly different than the plain encoding (1 byte less) System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_fail_compress_with_lzo_when_the_native_library_is_not_loaded() throws IOException { assertThatExceptionOfType(RuntimeException.class).isThrownBy(() -> CODEC_FACTORY.getCompressor(CompressionCodecName.LZO)) .withMessageContaining("native-lzo library not available");}private static final byte getUtf8(String text) { try { return text.getBytes("UTF-8"); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e); }}
La compressione è una delle altre armi di Parquet per la battaglia contro lo storage inefficiente. È complementare ai metodi di codifica già spiegati e può essere applicata anche a livello di colonna. Questo porta alla possibilità di utilizzare diversi metodi di compressione, a seconda dei dati contenuti. Apache Parquet fornisce 3 codec di compressione dettagliati nella seconda sezione: gzip, Snappy e LZO. I primi due sono inclusi nativamente, mentre l’ultimo richiede alcune impostazioni aggiuntive. Come mostrato nella sezione finale, la compressione non è sempre positiva. A volte i dati compressi occupano più posto di quelli non compressi. Lo spiegheremmo con un overhead extra portato dalla codifica delle informazioni.
TAGS: #Algoritmi di compressione