Versiones: Parquet 1.9.0
La última vez hemos descubierto diferentes métodos de codificación disponibles en Apache Parquet. Pero la codificación no es la única técnica que ayuda a reducir el tamaño de los archivos. La otra, muy parecida, es la compresión.
Este post da una visión sobre la compresión que ofrece Apache Parquet. Sin embargo, la primera parte recuerda los fundamentos y se centra en la compresión como un proceso independiente de cualquier marco. Sólo la segunda sección enumera y explica los códecs de compresión disponibles en Parquet. La última sección muestra algunas pruebas de compresión.
Definición de compresión
La compresión de datos es una técnica cuyo objetivo principal es la reducción del tamaño lógico del archivo. Así que el archivo reducido debe ocupar menos lugar en el disco y ser transferido más rápido a través de la red. Muy a menudo la compresión funciona de forma similar a la codificación. Identifica patrones repetitivos y los sustituye por representaciones más compactas.
La diferencia entre codificación y compresión es sutil. La codificación cambia la representación de los datos. Por ejemplo, puede representar la palabra «abc» como «11» y a menudo puede basarse en los mismos principios que la compresión. Un ejemplo de ello es la codificación Run-Length, que sustituye los símbolos repetidos (por ejemplo, «aaa») por una forma más corta («3a»). Por otro lado, la compresión se ocupa de toda la información y aprovecha la redundancia de datos para reducir el tamaño total. Por ejemplo, puede eliminar las partes de información que son inútiles (por ejemplo, patrones repetidos o piezas de información sin sentido para el receptor).
Codecs de compresión en Parquet
La compresión en Parquet se realiza por columna. Excepto la representación sin comprimir, Apache Parquet viene con 3 códecs de compresión:
- gzip – método de compresión sin pérdidas bastante popular basado en el algoritmo DEFLATE siendo una combinación de codificación Huffman y LZ77.
La codificación Huffman es una técnica de longitud variable que asigna códigos más pequeños para los caracteres más utilizados. Por ejemplo, si quisiéramos codificar la palabra «aaaaabbbc» con 2 bits, utilizaríamos 9*2 = 18 bits. Por otro lado, codificar esta secuencia de caracteres con la codificación Huffman podría reducir el número de bits a 5+3*2+2 = 13 bits, donde el carácter más frecuente «a» se codifica como 0 y otros dos en los 2 bits habituales. Era una explicación sencilla. Más exactamente, la codificación Huffman funciona combinando árboles con nodos que representan los caracteres del valor codificado. Cada nodo representa un carácter y está etiquetado con el peso del carácter (= el número de ocurrencias). El algoritmo comienza con árboles de 1 nodo que se combinan paso a paso hasta que sólo hay 1 árbol. El paso de fusión consiste en elegir 2 árboles con los menores pesos y combinarlos. Al final, la codificación se resuelve definiendo una regla de codificación. Por ejemplo la regla de codificación puede decir que todos los valores de la izquierda se codifican con 1 y los de la derecha con 0. Este algoritmo se presenta en la siguiente imagen: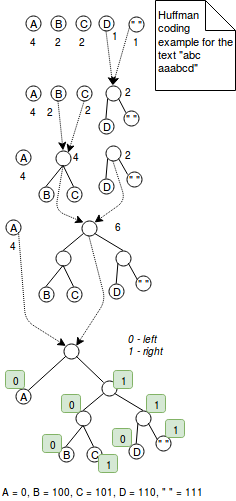
Por otro lado, LZ77 representa la información repetida en tripletas más concisas de (distancia, longitud). Por ejemplo, si codificamos el texto «ABAC» con LZ77, se representará como «AB(2,1)C». La imagen de abajo explica mejor los pasos de este método: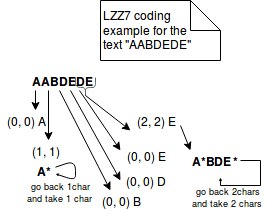
- Snappy – Snappy es de código abierto por Google, método de compresión orientado a bytes (se emiten o consumen bytes enteros de un flujo). El formato comprimido comienza con un campo que indica la longitud de los datos sin comprimir. Posteriormente, los datos comprimidos se representan como literales o como copias. Ambas representaciones se incluyen en una estructura denominada tag byte. Los 2 bytes bajos de esta estructura indican la representación utilizada (00 para los literales, 01, 10, 11 para las copias).
Literal se utiliza para representar los datos que no pueden ser comprimidos. Tiene un concepto de longitud que puede ser almacenado en 2 lugares diferentes. Para los literales de hasta 60 bytes, la longitud se almacena directamente en el byte de la etiqueta. Para los literales más grandes, la longitud se almacena directamente después del byte de la etiqueta. En este caso, el byte de la etiqueta sólo contiene la información sobre el lugar que ocupa la longitud.
El segundo tipo de representación se llama copia. Utiliza un concepto similar al de la codificación LZ77, ya que representa los datos repetidos en tuplas de (offset, longitud). Dependiendo de la longitud de la tupla, podemos distinguir 3 tipos diferentes de copias:- La copia con offset de 1 byte codifica las longitudes entre 4 y 11 bytes. En el byte de la etiqueta se prefija con 01 en el byte de la etiqueta.
- Para la copia con offset de 2 bytes las longitudes entre 1 y 64 bytes se prefijan con 10 en el byte de la etiqueta. La información de desplazamiento se almacena en 2 bytes a continuación del byte de etiqueta como un int little-endian de 16 bits.
- La copia con desplazamiento de 4 bytes se representa como 11 en el byte de etiqueta. Tiene características similares a la copia anterior. La única diferencia es el almacenamiento del offset que es un entero de 32 bits.
Sin embargo, Snappy no es una codificación puramente LZ77. Es más bien un estilo LZ. LZ77 consta de 2 partes: algoritmo de coincidencia que reconoce las repeticiones y codificación. Snappy se salta la última parte porque utiliza un formato de empaquetado de literales y copias fijo y ajustado a mano.
- LZO – método de compresión basado en diccionario y sin pérdidas. Favorece la velocidad de compresión sobre el ratio de compresión. El LZO pertenece a la familia de las codificaciones LZ porque es la variación del LZ77. La diferencia es que está optimizada para aprovechar el hecho de que los ordenadores actuales están optimizados para realizar operaciones con números enteros. Aporta tablas de búsqueda hash tan rápidas y tokens de salida mejor optimizados. Los datos que no se pueden comprimir se copian sin comprimir en el flujo de salida en una base de palabras largas de 32 bits.
A diferencia de los 2 métodos de compresión anteriores, la compresión LZO necesita algo de trabajo adicional. Una biblioteca nativa LZO debe ser instalado por separado y algunas soluciones se dio en StackOverflow: Hadoop-LZO strange native-lzo library not available error o Class com.hadoop.compression.lzo.LzoCodec not found for Spark on CDH 5?
Ejemplos de compresión de Parquet
En las siguientes pruebas, debido a la complejidad de la instalación de LZO, sólo se presentan los codecs gzip y Snappy:
private static final CodecFactory CODEC_FACTORY = new CodecFactory(new Configuration(), 1024);private static final CodecFactory.BytesCompressor GZIP_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.GZIP);private static final CodecFactory.BytesCompressor SNAPPY_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.SNAPPY);private static final BytesInput BIG_INPUT_INTS;static { List<BytesInput> first4000Numbers = IntStream.range(1, 4000).boxed().map(number -> BytesInput.fromInt(number)).collect(Collectors.toList()); BIG_INPUT_INTS = BytesInput.concat(first4000Numbers);}private static final BytesInput SMALL_INPUT_STRING = BytesInput.concat( BytesInput.from(getUtf8("test")), BytesInput.from(getUtf8("test1")), BytesInput.from(getUtf8("test2")), BytesInput.from(getUtf8("test3")), BytesInput.from(getUtf8("test4")));private static final BytesInput INPUT_DATA_STRING;private static final BytesInput INPUT_DATA_STRING_DISTINCT_WORDS;static { URL url = Resources.getResource("lorem_ipsum.txt"); try { String text = Resources.toString(url, Charset.forName("UTF-8")); INPUT_DATA_STRING = BytesInput.from(getUtf8(text)); String textWithDistinctWords = Stream.of(text.split(" ")).distinct().collect(Collectors.joining(", ")); INPUT_DATA_STRING_DISTINCT_WORDS = BytesInput.from(getUtf8(textWithDistinctWords)); } catch (IOException e) { throw new RuntimeException(e); }}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(SMALL_INPUT_STRING); // Compressed size is greater because GZIP adds some additional compression metadata as, header // It can be seen in java.util.zip.GZIPOutputStream.writeHeader() System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(BIG_INPUT_INTS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(SMALL_INPUT_STRING); // For snappy the difference is much less smaller than in the case of Gzip (1 byte) // The difference comes from the fact that Snappy stores the length of compressed output after // the compressed values // You can see that in the Snappy implementation C++ header file: // https://github.com/google/snappy/blob/32d6d7d8a2ef328a2ee1dd40f072e21f4983ebda/snappy.h#L111 System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(BIG_INPUT_INTS); // Snappy is only slightly different than the plain encoding (1 byte less) System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_fail_compress_with_lzo_when_the_native_library_is_not_loaded() throws IOException { assertThatExceptionOfType(RuntimeException.class).isThrownBy(() -> CODEC_FACTORY.getCompressor(CompressionCodecName.LZO)) .withMessageContaining("native-lzo library not available");}private static final byte getUtf8(String text) { try { return text.getBytes("UTF-8"); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e); }}
La compresión es una de las otras armas de Parquet para la batalla contra el almacenamiento ineficiente. Es complementaria a los métodos de codificación ya explicados y puede aplicarse también a nivel de columna. Eso trae la posibilidad de usar diferentes métodos de compresión, de acuerdo a los datos contenidos. Apache Parquet proporciona 3 códecs de compresión detallados en la 2ª sección: gzip, Snappy y LZO. Los dos primeros se incluyen de forma nativa, mientras que el último requiere alguna configuración adicional. Como se muestra en la última sección, la compresión no siempre es positiva. A veces los datos comprimidos ocupan más lugar que los no comprimidos. Lo explicaríamos por una sobrecarga extra que conlleva la codificación de la información.
TAGS: #Algoritmos de compresión