Geralmente, para qualquer problema de classificação, prevemos o valor da classe que tem a maior probabilidade de ser a verdadeira etiqueta de classe. Contudo, por vezes, queremos prever as probabilidades de uma instância de dados pertencente a cada etiqueta de classe. Por exemplo, digamos que estamos a construir um modelo para classificar frutas e temos três etiquetas de classe: maçãs, laranjas, e bananas (cada fruta é uma delas). Para qualquer fruta, queremos que as probabilidades da fruta ser uma maçã, uma laranja, ou uma banana.
Isto é muito útil para a avaliação de um modelo de classificação. Pode ajudar-nos a compreender o quão ‘seguro’ é um modelo ao mesmo tempo que prevê um rótulo de classe e pode ajudar-nos a interpretar o quão decisivo é um modelo de classificação. Geralmente, os classificadores que têm uma probabilidade linear de prever as etiquetas de cada classe são chamados calibrados. O problema é que nem todos os modelos de classificação são calibrados.
alguns modelos podem dar estimativas pobres de probabilidades de classe e alguns nem sequer suportam a previsão de probabilidades.
Calibração de curvas:
As curvas de calibração são usadas para avaliar como é calibrado um classificador, ou seja, como as probabilidades de previsão de cada etiqueta de classe diferem. O eixo x representa a probabilidade média prevista em cada contentor. O eixo y é o rácio de positivos (a proporção de previsões positivas). A curva do modelo calibrado ideal é uma linha recta linear a partir de (0, 0) movendo-se linearmente.
Curvas de Calibração de Plotting em Python3:
Para este exemplo, vamos utilizar um conjunto de dados binários. Utilizaremos o popular conjunto de dados sobre diabetes. Pode saber mais sobre este conjunto de dados aqui.
Código: Implementar uma curva de calibração da Máquina Vectorial de Suporte e compará-la com a curva de um modelo perfeitamente calibrado.
>/p>
fromsklearn.datasets importload_breast_cancer fromsklearn.svm importSVC fromsklearn.model_selection importtrain_test_split fromsklearn.calibration importcalibration_curve importmatplotlib.pyplot as plt dataset =load_breast_cancer() X =dataset.data y =dataset.target X_train, X_test, y_train, y_test =train_test_split(X, y, test_size =0.1, random_state =13) model =SVC() model.fit(X_train, y_train) prob =model.decision_function(X_test) x, y =calibration_curve(y_test, prob, n_bins =10, normalize =True) plt.plot(, , linestyle ='--', label ='Ideally Calibrated') plt.plot(y, x, marker ='.', label ='Support Vector Classifier') leg =plt.legend(loc ='upper left') plt.xlabel('Average Predicted Probability in each bin') 'Ratio of positives') plt.show() br>>>/div>
Eliminar:
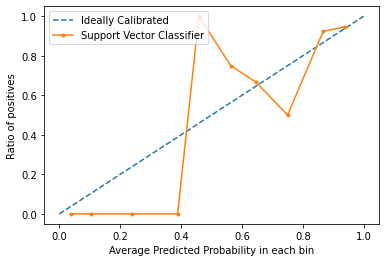
Do gráfico, podemos ver claramente que o classificador Suppor Vector não está nem muito bem calibrado. O fechamento da curva de um modelo é para a curva do modelo perfeitamente calibrado (curva pontilhada), quanto melhor calibrado estiver.
Conclusão:
Agora que sabe o que é a calibração em termos de Aprendizagem de Máquina e como traçar uma curva de calibração, da próxima vez que o classificador der resultados imprevisíveis e não conseguir encontrar a causa, tente traçar a curva de calibração e verifique se o modelo está bem calibrado.
