p>Design de Experiências > Fiabilidade entre avaliadores
O que é a Fiabilidade entre avaliadores?
Fiabilidade entre avaliadores é o nível de concordância entre avaliadores ou juízes. Se todos concordarem, a TIR é 1 (ou 100%) e se todos discordarem, a TIR é 0 (0%). Existem vários métodos para calcular a TIR, desde o simples (por exemplo, o acordo percentual) até ao mais complexo (por exemplo, o Kappa de Cohen). Qual deles escolher depende largamente do tipo de dados que tiver e quantos avaliadores estão no seu modelo.
Métodos de Fiabilidade entre Avaliadores
Concordância Percentual para Duas Avaliadoras
A medida básica para a fiabilidade entre avaliadores é uma concordância percentual entre avaliadores.
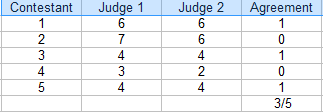 p> Neste concurso, os juízes concordaram em 3 das 5 pontuações. A concordância percentual é 3/5 = 60%.
p> Neste concurso, os juízes concordaram em 3 das 5 pontuações. A concordância percentual é 3/5 = 60%. Para encontrar concordância percentual para dois avaliadores, uma tabela (como a anterior) é útil.
- Contar o número de classificações de acordo. Na tabela acima, isso é 3.
- Contar o número total de classificações. Para este exemplo, isso é 5.
- Dividir o total pelo número em concordância para obter uma fracção: 3/5.
- Converter para uma percentagem: 3/5 = 60%.
O campo em que está a trabalhar determinará o nível de concordância aceitável. Se for uma competição desportiva, poderá aceitar um acordo de 60% para decidir um vencedor. Contudo, se estiver a olhar para dados de especialistas em cancro a decidir sobre um curso de tratamento, vai querer um acordo muito superior – acima de 90%. Em geral, acima de 75% é considerado aceitável para a maioria dos campos.
Acordo de Percentagem para múltiplos avaliadores
Se tiver múltiplos avaliadores, calcule a percentagem de acordo da seguinte forma:
Etapa 1: Faça uma tabela das suas classificações. Para este exemplo, existem três juízes: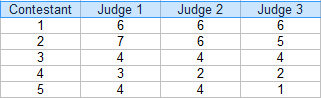 br>
br>
P>Passo 2: Adicione colunas adicionais para as combinações(pares) de juízes. Para este exemplo, os três pares possíveis são: J1/J2, J1/J3 e J2/J3.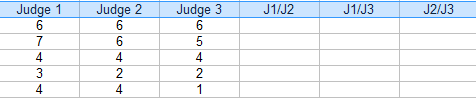 br>
br>
P>Passo 3: Para cada par, colocar um “1” para acordo e um “0” para acordo. Por exemplo, o concorrente 4, Juiz 1/Judge 2 discordou (0), Juiz 1/Judge 3 discordou (0) e Juiz 2 / Juiz 3 concordou (1).
passo 4: Somar os 1s e 0s numa coluna de Acordo:
passo 5: Encontrar a média das fracções na coluna Acordo.
Mean = (3/3 + 0/3 + 3/3 + 1/3 + 1/3) / 5 = 0,53, ou 53%.
A fiabilidade entre avaliadores para este exemplo é de 54%.
Desvantagens
Como provavelmente se pode dizer, calcular acordos percentuais para mais do que um punhado de avaliadores pode rapidamente tornar-se incómodo. Por exemplo, se tivesse 6 juízes, teria 16 combinações de pares para calcular para cada concorrente (use a nossa calculadora de combinações para descobrir quantos pares obteria para vários juízes).
Uma grande falha com este tipo de fiabilidade entre jurados é que não se leva em conta o acordo casual e se sobrestima o nível de concordância. Esta é a principal razão pela qual a concordância percentual não deve ser utilizada para trabalhos académicos (ou seja, dissertações ou publicações académicas).
Métodos Alternativos
Têm sido desenvolvidos métodos transversais que são mais fáceis de calcular (geralmente são incorporados em pacotes de software estatístico) e têm em conta o acaso:
- Se tiver um ou dois pares significativos, use a correlação Interclasse (equivalente ao Coeficiente de Correlação Pearson).
- Se tiver mais de um par, use a correlação Intraclasse. Este é um dos métodos mais populares de TIR e é utilizado para dois ou mais avaliadores.
- Kappa de Cohen: comummente utilizado para variáveis categóricas.
- Fleiss’ Kappa: semelhante à Kappa de Cohen, adequado quando se tem um número constante de m raters aleatoriamente amostrados de uma população de raters, com uma amostra diferente de m codificadores classificando cada sujeito.
- O Coeficiente AC2 da Gwet é calculado facilmente em Excel com o AgreeStat.com add on.
- Krippendorff’s Alpha é sem dúvida a melhor medida de fiabilidade entre avaliadores, mas é computacionalmente complexo.
Beyer, W. H. CRC Standard Mathematical Tables, 31st ed. Boca Raton, FL: CRC Press, pp. 536 e 571, 2002.
Everitt, B. S.; Skrondal, A. (2010), The Cambridge Dictionary of Statistics, Cambridge University Press.
Klein, G. (2013). The Cartoon Introduction to Statistics (Introdução à Estatística). Hill & Wamg.
Vogt, W.P. (2005). Dicionário de Estatística & Metodologia: Um Guia Não Técnico para as Ciências Sociais. SAGE.
Stephanie Glen. “Inter-rater Reliability IRR: Definição, Cálculo” de StatisticsHowTo.com: Estatísticas Elementares para o resto de nós! https://www.statisticshowto.com/inter-rater-reliability/
——————————————————————————
p>Need help with a homework or test question? Com o Chegg Study, pode obter soluções passo a passo para as suas perguntas de um especialista na matéria. Os seus primeiros 30 minutos com um tutor do Chegg são gratuitos!