Versions : Parquet 1.9.0
La dernière fois, nous avons découvert différentes méthodes d’encodage disponibles dans Apache Parquet. Mais l’encodage n’est pas la seule technique permettant de réduire la taille des fichiers. L’autre, très similaire, est la compression.
Ce billet donne un aperçu de la compression fournie par Apache Parquet. Cependant la première partie rappelle les bases et se concentre sur la compression en tant que processus indépendant de tout framework. Seule la deuxième section liste et explique les codecs de compression disponibles dans Parquet. La dernière section montre quelques tests de compression.
Définition de la compression
La compression de données est une technique dont le but principal est la réduction de la taille logique du fichier. Ainsi le fichier réduit doit prendre moins de place sur le disque et être transféré plus rapidement sur le réseau. Très souvent, la compression fonctionne de manière similaire à l’encodage. Elle identifie les motifs répétitifs et les remplace par des représentations plus compactes.
La différence entre l’encodage et la compression est subtile. L’encodage modifie la représentation des données. Par exemple, il peut représenter le mot « abc » par « 11 » et souvent il peut être basé sur les mêmes principes que la compression. Un exemple en est le Run-Length Encoding qui remplace les symboles répétés (par exemple « aaa ») par une forme plus courte (« 3a »). D’un autre côté, la compression traite l’ensemble des informations et tire parti de la redondance des données pour réduire la taille totale. Par exemple, elle peut supprimer les parties de l’information qui sont inutiles (par exemple, les motifs répétés ou les éléments d’information sans signification pour le récepteur).
Codecs de compression dans Parquet
La compression dans Parquet se fait par colonne. Hormis la représentation non compressée, Apache Parquet est livré avec 3 codecs de compression :
- gzip – méthode de compression sans perte assez populaire basée sur l’algorithme DEFLATE étant une combinaison du codage Huffman et de LZ77.
Le codage Huffman est une technique à longueur variable qui attribue des codes plus petits pour les caractères les plus fréquemment utilisés. Par exemple, si nous souhaitons coder le mot « aaaaabbbc » avec 2 bits, nous utiliserons 9*2 = 18 bits. De l’autre côté, l’encodage de cette séquence de caractères avec le codage de Huffman pourrait réduire le nombre de bits à 5+3*2+2 = 13 bits où le caractère le plus fréquent « a » est encodé comme 0 et les deux autres comme 2 bits habituels. C’était une explication simple. Plus précisément, le codage de Huffman fonctionne en combinant des arbres dont les nœuds représentent les caractères de la valeur codée. Chaque nœud représente un caractère et est étiqueté avec le poids du caractère (= le nombre d’occurrences). L’algorithme commence avec des arbres à 1 nœud qui sont combinés étape par étape jusqu’à ce qu’il n’y ait plus qu’un seul arbre. L’étape de fusion consiste à choisir 2 arbres avec les poids les plus faibles et à les combiner ensemble. A la fin, l’encodage est résolu en définissant une règle d’encodage. Par exemple la règle d’encodage peut dire que toutes les valeurs de gauche sont encodées avec 1 et celles de droite avec 0. Cet algorithme est présenté dans l’image ci-dessous :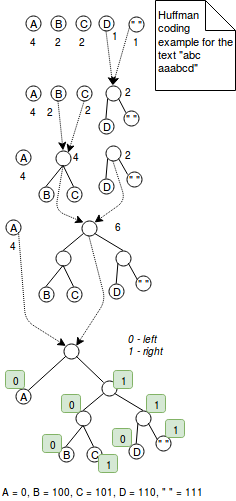
Dans l’autre côté, LZ77 représente les informations répétées dans des triplets plus concis de (distance, longueur). Par exemple, si nous codons le texte « ABAC » avec LZ77, il sera représenté par « AB(2,1)C ». L’image ci-dessous explique mieux les étapes de cette méthode :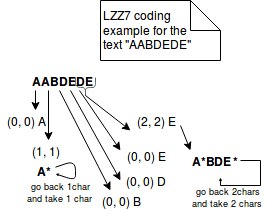
- Snappy – Snappy est une méthode de compression open-sourcée par Google, orientée octet (des octets entiers sont émis ou consommés à partir d’un flux). Le format compressé commence par un champ indiquant la longueur des données non compressées. Ensuite, les données compressées sont représentées soit sous forme de littéraux, soit sous forme de copies. Ces deux représentations sont incluses dans une structure appelée tag byte. Les 2 octets de poids faible de cette structure indiquent la représentation utilisée (00 pour les littéraux, 01, 10, 11 pour les copies).
Littéral est utilisé pour représenter les données qui ne peuvent pas être compressées. Il possède un concept de longueur qui peut être stocké à 2 endroits différents. Pour les littéraux jusqu’à 60 octets, la longueur est stockée directement dans l’octet de balise. Pour les littéraux plus grands, la longueur est stockée directement après l’octet de balise. Dans ce cas, l’octet de balise ne contient que l’information sur le nombre de place occupé par la longueur.
Le deuxième type de représentation est appelé copie. Il utilise un concept similaire à l’encodage LZ77 puisqu’il représente les données répétées dans des tuples de (offset, longueur). En fonction de la longueur du tuple, on peut distinguer 3 types différents de copies :- La copie avec un offset de 1 octet encode les longueurs entre 4 et 11 octets. Dans l’octet de balise, elle est préfixée par 01 dans l’octet de balise.
- Pour la copie avec décalage de 2 octets, les longueurs comprises entre 1 et 64 octets sont préfixées par 10 dans l’octet de balise. L’information de décalage est stockée dans 2 octets suivant l’octet de balise comme un int 16 bits little-endian.
- La copie avec décalage de 4 octets est représentée par 11 dans l’octet de balise. Elle a des caractéristiques similaires à la copie précédente. La seule différence est le stockage du décalage qui est un entier de 32 bits.
Cependant, Snappy n’est pas un encodage purement LZ77. Il s’agit plutôt d’un style LZ. LZ77 se compose de 2 parties : l’algorithme de correspondance qui reconnaît les répétitions et l’encodage. Snappy saute la dernière partie car il utilise un format d’emballage fixe et réglé à la main des littéraux et des copies.
- LZO – méthode de compression basée sur le dictionnaire et sans perte. Elle privilégie la vitesse de compression sur le taux de compression. Le LZO appartient à la famille des encodages LZ car c’est la variante du LZ77. La différence est qu’il est optimisé pour tirer parti du fait que les ordinateurs actuels sont optimisés pour effectuer des opérations sur des nombres entiers. Il apporte des tables de consultation de hachage plus rapides et des jetons de sortie mieux optimisés. Les données qui ne peuvent pas être comprimées sont copiées sous forme non comprimée dans le flux de sortie sur la base de mots longs de 32 bits.
À la différence des 2 méthodes de compression précédentes, la compression LZO nécessite un travail supplémentaire. Une bibliothèque native LZO doit être installée séparément et quelques solutions ont été données sur StackOverflow : Hadoop-LZO strange native-lzo library not available error ou Class com.hadoop.compression.lzo.LzoCodec not found for Spark on CDH 5 ?
Exemples de compression Parquet
Dans les tests ci-dessous, en raison de la complexité d’installation de LZO, seuls les codecs gzip et Snappy sont présentés:
private static final CodecFactory CODEC_FACTORY = new CodecFactory(new Configuration(), 1024);private static final CodecFactory.BytesCompressor GZIP_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.GZIP);private static final CodecFactory.BytesCompressor SNAPPY_COMPRESSOR = CODEC_FACTORY.getCompressor(CompressionCodecName.SNAPPY);private static final BytesInput BIG_INPUT_INTS;static { List<BytesInput> first4000Numbers = IntStream.range(1, 4000).boxed().map(number -> BytesInput.fromInt(number)).collect(Collectors.toList()); BIG_INPUT_INTS = BytesInput.concat(first4000Numbers);}private static final BytesInput SMALL_INPUT_STRING = BytesInput.concat( BytesInput.from(getUtf8("test")), BytesInput.from(getUtf8("test1")), BytesInput.from(getUtf8("test2")), BytesInput.from(getUtf8("test3")), BytesInput.from(getUtf8("test4")));private static final BytesInput INPUT_DATA_STRING;private static final BytesInput INPUT_DATA_STRING_DISTINCT_WORDS;static { URL url = Resources.getResource("lorem_ipsum.txt"); try { String text = Resources.toString(url, Charset.forName("UTF-8")); INPUT_DATA_STRING = BytesInput.from(getUtf8(text)); String textWithDistinctWords = Stream.of(text.split(" ")).distinct().collect(Collectors.joining(", ")); INPUT_DATA_STRING_DISTINCT_WORDS = BytesInput.from(getUtf8(textWithDistinctWords)); } catch (IOException e) { throw new RuntimeException(e); }}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(SMALL_INPUT_STRING); // Compressed size is greater because GZIP adds some additional compression metadata as, header // It can be seen in java.util.zip.GZIPOutputStream.writeHeader() System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_gzip_than_without_compression() throws IOException { BytesInput compressedLorem = GZIP_COMPRESSOR.compress(BIG_INPUT_INTS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_compress_lorem_ipsum_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());}@Testpublic void should_compress_text_without_repetitions_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS); System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size()); assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());}@Testpublic void should_compress_small_text_less_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(SMALL_INPUT_STRING); // For snappy the difference is much less smaller than in the case of Gzip (1 byte) // The difference comes from the fact that Snappy stores the length of compressed output after // the compressed values // You can see that in the Snappy implementation C++ header file: // https://github.com/google/snappy/blob/32d6d7d8a2ef328a2ee1dd40f072e21f4983ebda/snappy.h#L111 System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size()); assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());}@Testpublic void should_compress_ints_more_efficiently_with_snappy_than_without_compression() throws IOException { BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(BIG_INPUT_INTS); // Snappy is only slightly different than the plain encoding (1 byte less) System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size()); assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());}@Testpublic void should_fail_compress_with_lzo_when_the_native_library_is_not_loaded() throws IOException { assertThatExceptionOfType(RuntimeException.class).isThrownBy(() -> CODEC_FACTORY.getCompressor(CompressionCodecName.LZO)) .withMessageContaining("native-lzo library not available");}private static final byte getUtf8(String text) { try { return text.getBytes("UTF-8"); } catch (UnsupportedEncodingException e) { throw new RuntimeException(e); }}
La compression est l’une des autres armes de Parquet pour la bataille contre le stockage inefficace. Elle est complémentaire aux méthodes d’encodage déjà expliquées et peut être appliquée au niveau des colonnes également. Cela donne la possibilité d’utiliser différentes méthodes de compression, en fonction des données contenues. Apache Parquet fournit 3 codecs de compression détaillés dans la 2ème section : gzip, Snappy et LZO. Les deux premiers sont inclus nativement tandis que le dernier nécessite une configuration supplémentaire. Comme le montre la dernière section, la compression n’est pas toujours positive. Parfois, les données compressées occupent plus de place que les données non compressées. Nous expliquerions cela par un surcoût apporté par l’encodage des informations.
TAGS : #Algorithmes de compression