En general, para cualquier problema de clasificación, predecimos el valor de la clase que tiene la mayor probabilidad de ser la verdadera etiqueta de clase. Sin embargo, a veces queremos predecir las probabilidades de que una instancia de datos pertenezca a cada etiqueta de clase. Por ejemplo, supongamos que estamos construyendo un modelo para clasificar frutas y tenemos tres etiquetas de clase: manzanas, naranjas y plátanos (cada fruta es una de ellas). Para cualquier fruta, queremos las probabilidades de que la fruta sea una manzana, una naranja o un plátano.
Esto es muy útil para la evaluación de un modelo de clasificación. Puede ayudarnos a entender lo «seguro» que está un modelo al predecir una etiqueta de clase y puede ayudarnos a interpretar lo decisivo que es un modelo de clasificación. En general, los clasificadores que tienen una probabilidad lineal de predecir las etiquetas de cada clase se denominan calibrados. El problema es que no todos los modelos de clasificación están calibrados.
Algunos modelos pueden dar malas estimaciones de las probabilidades de las clases y otros ni siquiera admiten la predicción de probabilidades.
Curvas de calibración:
Las curvas de calibración se utilizan para evaluar cómo está calibrado un clasificador, es decir, cómo difieren las probabilidades de predecir cada etiqueta de clase. El eje x representa la probabilidad media de predicción en cada casilla. El eje y es la proporción de positivos (la proporción de predicciones positivas). La curva del modelo calibrado ideal es una línea recta desde (0, 0) que se mueve linealmente.
Planificación de las curvas de calibración en Python3:
Para este ejemplo, utilizaremos un conjunto de datos binarios. Utilizaremos el popular conjunto de datos de la diabetes. Puedes aprender más sobre este conjunto de datos aquí.
Código: Implementar la curva de calibración de una máquina de vectores de soporte y compararla con la curva de un modelo perfectamente calibrado.
fromsklearn.datasets importload_breast_cancer from sklearn.svm importSVC
fromsklearn.model_selection importtrain_test_split fromsklearn.calibration importcalibration_curve
importmatplotlib.pyplot as plt dataset =load_breast_cancer() X =dataset.data
y =dataset.target
X_train, X_test, y_train, y_test =train_test_split(X, y, test_size =0.1, random_state =13) model =SVC()
model.fit(X_train, y_train)
prob =model.decision_function(X_test)
x, y =calibration_curve(y_test, prob, n_bins =10, normalize =True)
plt.plot(, , linestyle ='--', label ='Ideally Calibrated')
plt.plot(y, x, marker ='.', label ='Support Vector Classifier')
leg =plt.legend(loc ='upper left') plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives')
plt.show() Salida:
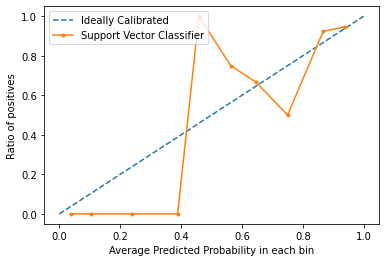
Desde el gráfico, podemos ver claramente que el clasificador de Vectores de Apoyo no está ni muy bien calibrado. Cuanto más se acerque la curva de un modelo a la curva del modelo perfectamente calibrado (curva punteada), mejor calibrado estará.
Conclusión:
Ahora que sabes qué es la calibración en términos de Machine Learning y cómo trazar una curva de calibración, la próxima vez que tu clasificador dé resultados imprevisibles y no encuentres la causa, prueba a trazar la curva de calibración y comprueba si el modelo está bien calibrado.
