Diseño de experimentos > Fiabilidad entre evaluadores
¿Qué es la fiabilidad entre evaluadores?
La fiabilidad intercalar es el nivel de acuerdo entre calificadores o jueces. Si todos están de acuerdo, la TIR es 1 (o 100%) y si todos están en desacuerdo, la TIR es 0 (0%). Existen varios métodos para calcular la TIR, desde los más sencillos (por ejemplo, el porcentaje de acuerdo) hasta los más complejos (por ejemplo, el Kappa de Cohen). El que elija depende en gran medida del tipo de datos que tenga y de cuántos calificadores haya en su modelo.
Métodos de fiabilidad entre calificadores
Porcentaje de acuerdo para dos calificadores
La medida básica para la fiabilidad entre calificadores es un porcentaje de acuerdo entre calificadores.
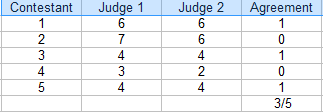
En esta competencia, los jueces estuvieron de acuerdo en 3 de 5 calificaciones. El porcentaje de acuerdo es 3/5 = 60%.
- Cuente el número de calificaciones de acuerdo. En la tabla anterior, es 3.
- Cuente el número total de valoraciones. Para este ejemplo, son 5.
- Divide el total por el número de acuerdo para obtener una fracción: 3/5.
- Convierte a porcentaje: 3/5 = 60%.
El ámbito en el que trabajes determinará el nivel de acuerdo aceptable. Si se trata de una competición deportiva, podría aceptar un acuerdo del 60% de los calificadores para decidir un ganador. Sin embargo, si se trata de datos de especialistas en cáncer que deciden un curso de tratamiento, querrá un acuerdo mucho mayor, por encima del 90%. En general, por encima del 75% se considera aceptable para la mayoría de los campos.
Porcentaje de acuerdo para múltiples calificadores
Si tiene múltiples calificadores, calcule el porcentaje de acuerdo de la siguiente manera:
Paso 1: Haga una tabla con sus calificaciones. Para este ejemplo, hay tres jueces: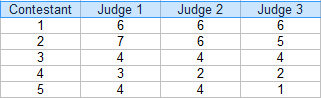
Paso 2: Añada columnas adicionales para las combinaciones(pares) de jueces. Para este ejemplo, los tres pares posibles son: J1/J2, J1/J3 y J2/J3.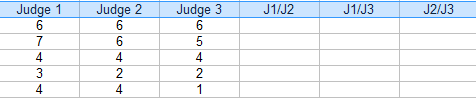
Paso 3: Para cada pareja, pon un «1» para el acuerdo y «0» para el acuerdo. Por ejemplo, concursante 4, Juez 1/Juez 2 en desacuerdo (0), Juez 1/Juez 3 en desacuerdo (0) y Juez 2 / Juez 3 de acuerdo (1).
Paso 4: Sume los 1s y 0s en una columna de Acuerdo:
Paso 5: Halla la media de las fracciones de la columna Acuerdo.
Media = (3/3 + 0/3 + 3/3 + 1/3 + 1/3) / 5 = 0,53, o 53%.
La fiabilidad entre calificadores para este ejemplo es del 54%.
Desventajas
Como probablemente pueda deducir, el cálculo de los acuerdos porcentuales para más de un puñado de calificadores puede volverse rápidamente engorroso. Por ejemplo, si tuvieras 6 jueces, tendrías 16 combinaciones de pares que calcular para cada concursante (utiliza nuestra calculadora de combinaciones para averiguar cuántos pares obtendrías para múltiples jueces).
Un defecto importante de este tipo de fiabilidad entre jueces es que no tiene en cuenta la concordancia por azar y sobreestima el nivel de concordancia. Esta es la razón principal por la que el porcentaje de acuerdo no debería utilizarse para trabajos académicos (es decir, disertaciones o publicaciones académicas).
Métodos alternativos
Se han desarrollado varios métodos que son más fáciles de calcular (normalmente están integrados en paquetes de software estadístico) y tienen en cuenta el azar:
- Si tiene uno o dos pares significativos, utilice la correlación interclase (equivalente al coeficiente de correlación de Pearson).
- Si tiene más de un par de pares, utilice la correlación intraclase. Este es uno de los métodos de TIR más populares y se utiliza para dos o más calificadores.
- Kappa de Cohen: se utiliza habitualmente para variables categóricas.
- Kappa de Fleiss: similar al Kappa de Cohen, adecuado cuando se tiene un número constante de m calificadores muestreados aleatoriamente de una población de calificadores, con una muestra diferente de m codificadores que califican a cada sujeto.
- El coeficiente AC2 de Gwet se calcula fácilmente en Excel con el complemento AgreeStat.com.
- El Alfa de Krippendorff es posiblemente la mejor medida de la fiabilidad inter-asociada, pero es computacionalmente compleja.
Beyer, W. H. CRC Standard Mathematical Tables, 31st ed., Boca Raton, FL. Boca Ratón, FL: CRC Press, pp. 536 y 571, 2002.
Everitt, B. S.; Skrondal, A. (2010), The Cambridge Dictionary of Statistics, Cambridge University Press.
Klein, G. (2013). La introducción de dibujos animados a la estadística. Hill & Wamg.
Vogt, W.P. (2005). Diccionario de estadística & Metodología: Una guía no técnica para las ciencias sociales. SAGE.
Stephanie Glen. «Inter-rater Reliability IRR: Definition, Calculation» De StatisticsHowTo.com: ¡Estadística elemental para el resto de nosotros! https://www.statisticshowto.com/inter-rater-reliability/
——————————————————————————
¿Necesitas ayuda con los deberes o con un examen? Con Chegg Study, puede obtener soluciones paso a paso a sus preguntas de un experto en la materia. ¡Tus primeros 30 minutos con un tutor de Chegg son gratis!