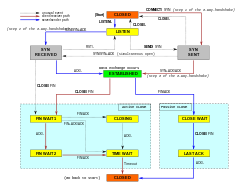
Le operazioni del protocollo TCP possono essere divise in tre fasi. La creazione della connessione è un processo di handshake a più fasi che stabilisce una connessione prima di entrare nella fase di trasferimento dei dati. Al termine del trasferimento dei dati, la terminazione della connessione chiude la connessione e rilascia tutte le risorse allocate.
Una connessione TCP è gestita da un sistema operativo attraverso una risorsa che rappresenta l’end-point locale per le comunicazioni, il socket Internet. Durante la durata di una connessione TCP, l’end-point locale subisce una serie di cambiamenti di stato:
| Stato | Endpoint | Descrizione | |
|---|---|---|---|
| LISTEN | Server | In attesa di una richiesta di connessione da qualsiasi punto finale TCPremoto. | |
| SYN-SENT | Client | In attesa di una richiesta di connessione corrispondente dopo aver inviato una richiesta di connessione. | |
| SYN-RECEIVED | Server | In attesa di una conferma della richiesta di connessione dopo aver ricevuto e inviato una richiesta di connessione. | |
| ESTABLISHED | Server e client | Un collegamento aperto, i dati ricevuti possono essere consegnati all’utente. Lo stato normale per la fase di trasferimento dati della connessione. | |
| FIN-WAIT-1 | Server e client | In attesa di una richiesta di terminazione della connessione dal TCP remoto, o un riconoscimento della richiesta di terminazione della connessione precedentemente inviata. | |
| FIN-WAIT-2 | Server e client | In attesa di una richiesta di terminazione della connessione dal TCP remoto. | |
| CLOSE-WAIT | Server e client | In attesa di una richiesta di terminazione della connessione dall’utente locale. | |
| CLOSING | Server e client | In attesa di un riconoscimento di richiesta di terminazione della connessione dal TCP remoto. | |
| LAST-ACK | Server e client | In attesa di un riconoscimento della richiesta di terminazione della connessione precedentemente inviata al TCP remoto (che include un riconoscimento della sua richiesta di terminazione della connessione). | |
| TIME-WAIT | Server o client | In attesa che passi abbastanza tempo per essere sicuri che il TCP remoto abbia ricevuto il riconoscimento della sua richiesta di terminazione della connessione. | |
| CHIUSO | Server e client | Nessuno stato di connessione. |
Stabilire la connessione
Prima che un client tenti di connettersi con un server, il server deve prima legarsi e ascoltare una porta per aprirla alle connessioni: questo è chiamato apertura passiva. Una volta che l’apertura passiva è stabilita, un client può stabilire una connessione iniziando un’apertura attiva usando l’handshake a tre vie (o 3 fasi):
- SYN: L’apertura attiva è eseguita dal client che invia un SYN al server. Il client imposta il numero di sequenza del segmento ad un valore casuale A.
- SYN-ACK: In risposta, il server risponde con un SYN-ACK. Il numero di riconoscimento è impostato su un valore superiore al numero di sequenza ricevuto, cioè A+1, e il numero di sequenza che il server sceglie per il pacchetto è un altro numero casuale, B.
- ACK: Infine, il client invia un ACK al server. Il numero di sequenza è impostato sul valore di riconoscimento ricevuto, cioè A+1, e il numero di riconoscimento è impostato su uno in più del numero di sequenza ricevuto, cioè B+1.
I passi 1 e 2 stabiliscono e confermano il numero di sequenza per una direzione. I passi 2 e 3 stabiliscono e confermano il numero di sequenza per l’altra direzione. Dopo il completamento di questi passi, sia il client che il server hanno ricevuto le conferme e viene stabilita una comunicazione full-duplex.
Terminazione della connessioneModifica

La fase di terminazione della connessione utilizza un handshake a quattro vie, con ogni lato della connessione che termina indipendentemente. Quando un endpoint desidera interrompere la sua metà della connessione, trasmette un pacchetto FIN, che l’altra estremità riconosce con un ACK. Pertanto, un tipico tear-down richiede una coppia di segmenti FIN e ACK da ogni endpoint TCP. Dopo che il lato che ha inviato il primo FIN ha risposto con l’ACK finale, attende un timeout prima di chiudere definitivamente la connessione, durante il quale la porta locale non è disponibile per nuove connessioni; questo previene la confusione dovuta ai pacchetti in ritardo che vengono consegnati durante le connessioni successive.
Una connessione può essere “semi-aperta”, nel qual caso un lato ha terminato la sua estremità, ma l’altro no. Il lato che ha terminato non può più inviare dati nella connessione, ma l’altro lato sì. Il lato che termina dovrebbe continuare a leggere i dati finché anche l’altro lato termina.
È anche possibile terminare la connessione con un handshake a 3 vie, quando l’host A invia un FIN e l’host B risponde con un FIN & ACK (combina semplicemente 2 passi in uno) e l’host A risponde con un ACK.
Alcuni sistemi operativi, come Linux e H-UX, implementano una sequenza di chiusura half-duplex nello stack TCP. Se l’host chiude attivamente una connessione, mentre ha ancora dati in entrata non letti disponibili, l’host invia il segnale RST (perdendo qualsiasi dato ricevuto) invece di FIN. Questo assicura un’applicazione TCP che il processo remoto ha letto tutti i dati trasmessi aspettando il segnale FIN, prima di chiudere attivamente la connessione. Il processo remoto non può distinguere tra un segnale RST per l’interruzione della connessione e la perdita di dati. Entrambi causano allo stack remoto la perdita di tutti i dati ricevuti.
Alcune applicazioni che utilizzano il protocollo TCP open/close handshaking possono trovare il problema RST sulla chiusura attiva. Come esempio:
s = connect(remote);send(s, data);close(s);
Per un flusso di programma come quello sopra, uno stack TCP/IP come quello descritto sopra non garantisce che tutti i dati arrivino all’altra applicazione se i dati non letti sono arrivati a questa estremità.
Uso delle risorseModifica
La maggior parte delle implementazioni alloca una voce in una tabella che mappa una sessione ad un processo del sistema operativo in esecuzione. Poiché i pacchetti TCP non includono un identificatore di sessione, entrambi gli endpoint identificano la sessione usando l’indirizzo e la porta del client. Ogni volta che un pacchetto viene ricevuto, l’implementazione TCP deve eseguire una ricerca su questa tabella per trovare il processo di destinazione. Ogni voce nella tabella è nota come Transmission Control Block o TCB. Contiene informazioni sugli endpoint (IP e porta), lo stato della connessione, i dati in esecuzione sui pacchetti che vengono scambiati e i buffer per l’invio e la ricezione dei dati.
Il numero di sessioni nel lato server è limitato solo dalla memoria e può crescere man mano che arrivano nuove connessioni, ma il client deve allocare una porta casuale prima di inviare il primo SYN al server. Questa porta rimane allocata durante l’intera conversazione, e limita efficacemente il numero di connessioni in uscita da ciascuno degli indirizzi IP del client. Se un’applicazione non riesce a chiudere correttamente le connessioni non richieste, un client può esaurire le risorse e diventare incapace di stabilire nuove connessioni TCP, anche da altre applicazioni.
Entrambi gli endpoint devono anche allocare spazio per i pacchetti non riconosciuti e i dati ricevuti (ma non letti).
Trasferimento datiModifica
Il Transmission Control Protocol differisce per diverse caratteristiche chiave dallo User Datagram Protocol:
- Trasferimento dati ordinato: l’host di destinazione riorganizza i segmenti secondo un numero di sequenza
- Ritrasmissione dei pacchetti persi: qualsiasi flusso cumulativo non riconosciuto viene ritrasmesso
- Trasferimento dati senza errori
- Controllo del flusso: limita la velocità con cui un mittente trasferisce i dati per garantire una consegna affidabile. Il ricevitore suggerisce continuamente al mittente quanti dati possono essere ricevuti (controllato dalla finestra scorrevole). Quando il buffer dell’host ricevente si riempie, il prossimo riconoscimento contiene uno 0 nella dimensione della finestra, per fermare il trasferimento e permettere ai dati nel buffer di essere elaborati.
- Controllo della congestione
Trasmissione affidabileModifica
TCP usa un numero di sequenza per identificare ogni byte di dati. Il numero di sequenza identifica l’ordine dei byte inviati da ogni computer in modo che i dati possano essere ricostruiti in ordine, indipendentemente da qualsiasi riordino dei pacchetti o perdita di pacchetti che può verificarsi durante la trasmissione. Il numero di sequenza del primo byte è scelto dal trasmettitore per il primo pacchetto, che è contrassegnato come SYN. Questo numero può essere arbitrario, e dovrebbe, in effetti, essere imprevedibile per difendersi dagli attacchi TCP di predizione della sequenza.
Le conferme (ACK) sono inviate con un numero di sequenza dal ricevitore di dati per dire al mittente che i dati sono stati ricevuti fino al byte specificato. Gli ACK non implicano che i dati siano stati consegnati all’applicazione. Significano semplicemente che è ora responsabilità del ricevitore consegnare i dati.
L’affidabilità è ottenuta dal mittente che rileva i dati persi e li ritrasmette. TCP usa due tecniche principali per identificare la perdita. Il timeout di ritrasmissione (abbreviato in RTO) e gli acknowledgements cumulativi duplicati (DupAcks).
Ritrasmissione basata su DupackModifica
Se un singolo segmento (diciamo il segmento 100) in un flusso viene perso, allora il ricevitore non può riconoscere i pacchetti superiori a no. 100 perché utilizza ACK cumulativi. Quindi il ricevitore riconosce nuovamente il pacchetto 99 alla ricezione di un altro pacchetto di dati. Questo duplice riconoscimento è usato come un segnale di perdita del pacchetto. Cioè, se il mittente riceve tre doppie conferme, ritrasmette l’ultimo pacchetto non riconosciuto. Una soglia di tre è usata perché la rete può riordinare i segmenti causando doppie conferme. Questa soglia ha dimostrato di evitare ritrasmissioni spurie dovute al riordino. A volte si usano le conferme selettive (SACK) per fornire un feedback esplicito sui segmenti che sono stati ricevuti. Questo migliora notevolmente la capacità del TCP di ritrasmettere i segmenti giusti.
Ritrasmissione basata sul timeoutModifica
Quando un mittente trasmette un segmento, inizializza un timer con una stima prudente del tempo di arrivo della conferma. Il segmento viene ritrasmesso se il timer scade, con una nuova soglia di timeout pari al doppio del valore precedente, con conseguente comportamento di backoff esponenziale. Tipicamente, il valore iniziale del timer è RTT lisciato + max ( G , 4 × variazione RTT ) {\displaystyle {\text{ RTT lisciato}}+\max(G, 4 volte {\text{ variazione RTT}})}

, dove G {displaystyle G}

è la granularità del clock. Questo protegge da un eccessivo traffico di trasmissione dovuto ad attori difettosi o malintenzionati, come gli attaccanti man-in-the-middle denial of service.
Rilevamento degli erroriModifica
I numeri di sequenza permettono ai ricevitori di scartare i pacchetti duplicati e di riordinare correttamente la sequenza dei pacchetti. I riconoscimenti permettono ai mittenti di determinare quando ritrasmettere i pacchetti persi.
Per assicurare la correttezza è incluso un campo checksum; vedi la sezione sul calcolo del checksum per dettagli sul checksum. Il checksum TCP è un controllo debole per gli standard moderni. I livelli di collegamento dati con alti tassi di errore di bit possono richiedere ulteriori capacità di correzione/individuazione degli errori di collegamento. Il checksum debole è parzialmente compensato dall’uso comune di un CRC o un controllo di integrità migliore al livello 2, sotto sia TCP che IP, come è usato in PPP o nel frame Ethernet. Tuttavia, questo non significa che il checksum TCP a 16 bit sia ridondante: notevolmente, l’introduzione di errori nei pacchetti tra gli hop protetti da CRC è comune, ma il checksum TCP a 16 bit end-to-end cattura la maggior parte di questi semplici errori. Questo è il principio end-to-end al lavoro.
Controllo del flussoModifica
TCP usa un protocollo di controllo del flusso end-to-end per evitare che il mittente invii dati troppo velocemente perché il ricevitore TCP possa riceverli ed elaborarli in modo affidabile. Avere un meccanismo di controllo del flusso è essenziale in un ambiente in cui comunicano macchine con diverse velocità di rete. Per esempio, se un PC invia dati a uno smartphone che sta elaborando lentamente i dati ricevuti, lo smartphone deve regolare il flusso di dati per non essere sopraffatto.
TCP utilizza un protocollo di controllo di flusso a finestra scorrevole. In ogni segmento TCP, il ricevitore specifica nel campo della finestra di ricezione la quantità di dati aggiuntivi ricevuti (in byte) che è disposto a bufferizzare per la connessione. L’host che invia può inviare solo fino a quella quantità di dati prima di dover attendere una conferma e un aggiornamento della finestra dall’host ricevente.

Quando un ricevitore pubblicizza una dimensione della finestra pari a 0, il mittente smette di inviare dati e avvia il persist timer. Il persist timer è usato per proteggere il TCP da una situazione di stallo che potrebbe verificarsi se un successivo aggiornamento della dimensione della finestra dal ricevitore viene perso, e il mittente non può inviare altri dati fino a quando non riceve un nuovo aggiornamento della dimensione della finestra dal ricevitore. Quando il timer persist scade, il mittente TCP tenta il recupero inviando un piccolo pacchetto in modo che il ricevitore risponda inviando un’altra conferma contenente la nuova dimensione della finestra.
Se un ricevitore sta elaborando i dati in arrivo in piccoli incrementi, può ripetutamente pubblicizzare una piccola finestra di ricezione. Questo viene chiamato la sindrome della finestra sciocca, poiché è inefficiente inviare solo pochi byte di dati in un segmento TCP, dato l’overhead relativamente grande dell’intestazione TCP.
Controllo della congestioneModifica
L’ultimo aspetto principale del TCP è il controllo della congestione. Il TCP utilizza un certo numero di meccanismi per raggiungere alte prestazioni ed evitare il collasso della congestione, dove le prestazioni della rete possono diminuire di diversi ordini di grandezza. Questi meccanismi controllano il tasso di dati che entrano nella rete, mantenendo il flusso di dati al di sotto di un tasso che innescherebbe il collasso. Essi producono anche un’allocazione approssimativamente equa max-min tra i flussi.
I riconoscimenti per i dati inviati, o la mancanza di riconoscimenti, sono usati dai mittenti per dedurre le condizioni della rete tra il mittente e il ricevitore TCP. Insieme ai timer, i mittenti e i ricevitori TCP possono alterare il comportamento del flusso di dati. Questo è più generalmente indicato come controllo della congestione e/o evitamento della congestione di rete.
Le moderne implementazioni del TCP contengono quattro algoritmi intrecciati: avvio lento, evitamento della congestione, ritrasmissione veloce e recupero veloce (RFC 5681).
Inoltre, i mittenti impiegano un timeout di ritrasmissione (RTO) che è basato sul tempo stimato di andata e ritorno (o RTT) tra il mittente e il ricevitore, così come la varianza di questo tempo di andata e ritorno. Il comportamento di questo timer è specificato in RFC 6298. Ci sono sottigliezze nella stima del RTT. Per esempio, i mittenti devono fare attenzione quando calcolano i campioni RTT per i pacchetti ritrasmessi; tipicamente usano l’algoritmo di Karn o i timestamp TCP (vedi RFC 1323). Questi campioni RTT individuali sono poi mediati nel tempo per creare uno Smoothed Round Trip Time (SRTT) usando l’algoritmo di Jacobson. Questo valore SRTT è quello che viene infine usato come stima del tempo di andata e ritorno.
Migliorare il TCP per gestire in modo affidabile le perdite, minimizzare gli errori, gestire la congestione e andare veloce in ambienti ad alta velocità sono aree di ricerca e sviluppo di standard in corso. Come risultato, ci sono un certo numero di varianti dell’algoritmo di prevenzione della congestione TCP.
Dimensione massima del segmentoModifica
La dimensione massima del segmento (MSS) è la più grande quantità di dati, specificata in byte, che TCP è disposto a ricevere in un singolo segmento. Per ottenere le migliori prestazioni, l’MSS dovrebbe essere impostato abbastanza piccolo da evitare la frammentazione IP, che può portare alla perdita di pacchetti e ad eccessive ritrasmissioni. Per cercare di raggiungere questo obiettivo, tipicamente l’MSS viene annunciato da ogni parte usando l’opzione MSS quando la connessione TCP viene stabilita, nel qual caso è derivato dalla dimensione dell’unità di trasmissione massima (MTU) del livello di collegamento dati delle reti a cui il mittente e il ricevitore sono direttamente collegati. Inoltre, i mittenti TCP possono usare il path MTU discovery per dedurre il minimo MTU lungo il percorso di rete tra il mittente e il ricevitore, e usarlo per regolare dinamicamente l’MSS per evitare la frammentazione IP all’interno della rete.
L’annuncio MSS è spesso chiamato anche “negoziazione MSS”. In senso stretto, l’MSS non è “negoziato” tra l’originatore e il ricevitore, perché ciò implicherebbe che sia l’originatore che il ricevitore negozieranno e si accorderanno su un singolo, unificato MSS che si applica a tutte le comunicazioni in entrambe le direzioni della connessione. Infatti, due valori completamente indipendenti di MSS sono permessi per le due direzioni del flusso di dati in una connessione TCP. Questa situazione può verificarsi, per esempio, se uno dei dispositivi che partecipano a una connessione ha una quantità estremamente limitata di memoria riservata (forse persino più piccola del Path MTU complessivo scoperto) per elaborare i segmenti TCP in arrivo.
Riconoscimenti selettiviModifica
Fare affidamento solo sullo schema di riconoscimento cumulativo impiegato dal protocollo TCP originale può portare a inefficienze quando i pacchetti vengono persi. Per esempio, supponiamo che i byte con numero di sequenza da 1.000 a 10.999 siano inviati in 10 diversi segmenti TCP di uguale dimensione, e che il secondo segmento (numeri di sequenza da 2.000 a 2.999) sia perso durante la trasmissione. In un protocollo di riconoscimento cumulativo puro, il ricevitore può solo inviare un valore ACK cumulativo di 2.000 (il numero di sequenza immediatamente successivo all’ultimo numero di sequenza dei dati ricevuti) e non può dire di aver ricevuto con successo i byte da 3.000 a 10.999. Quindi il mittente potrebbe dover reinviare tutti i dati a partire dal numero di sequenza 2.000.
Per alleviare questo problema il TCP impiega l’opzione di riconoscimento selettivo (SACK), definita nel 1996 in RFC 2018, che permette al ricevitore di riconoscere blocchi discontinui di pacchetti che sono stati ricevuti correttamente, oltre al numero di sequenza immediatamente successivo all’ultimo numero di sequenza dell’ultimo byte contiguo ricevuto successivamente, come nel riconoscimento TCP di base. L’acknowledgement può specificare un numero di blocchi SACK, dove ogni blocco SACK è veicolato dal Left Edge of Block (il primo numero di sequenza del blocco) e dal Right Edge of Block (il numero di sequenza immediatamente successivo all’ultimo numero di sequenza del blocco), con un Block che è un intervallo contiguo che il ricevitore ha ricevuto correttamente. Nell’esempio precedente, il ricevitore invierebbe un segmento ACK con un valore ACK cumulativo di 2.000 e un’intestazione di opzione SACK con numeri di sequenza 3.000 e 11.000. Il mittente ritrasmetterebbe di conseguenza solo il secondo segmento con numeri di sequenza da 2.000 a 2.999.
Un mittente TCP può interpretare una consegna di un segmento fuori ordine come un segmento perso. Se lo fa, il mittente TCP ritrasmetterà il segmento precedente al pacchetto fuori ordine e rallenterà la sua velocità di consegna dei dati per quella connessione. L’opzione duplicate-SACK, un’estensione dell’opzione SACK definita nel maggio 2000 in RFC 2883, risolve questo problema. Il ricevitore TCP invia un D-ACK per indicare che nessun segmento è stato perso, e il mittente TCP può quindi ripristinare la velocità di trasmissione superiore.
L’opzione SACK non è obbligatoria, ed entra in funzione solo se entrambe le parti la supportano. Viene negoziata quando viene stabilita una connessione. SACK usa un’opzione dell’intestazione TCP (vedi struttura del segmento TCP per i dettagli). L’uso di SACK è diventato molto diffuso – tutti gli stack TCP popolari lo supportano. Il riconoscimento selettivo è usato anche nello Stream Control Transmission Protocol (SCTP).
Window scalingEdit
Per un uso più efficiente delle reti ad alta larghezza di banda, può essere usata una dimensione della finestra TCP più grande. Il campo TCP window size controlla il flusso di dati e il suo valore è limitato a un valore compreso tra 2 e 65.535 byte.
Siccome il campo size non può essere espanso, viene utilizzato un fattore di scala. L’opzione TCP window scale, come definita in RFC 1323, è un’opzione usata per aumentare la dimensione massima della finestra da 65.535 byte a 1 gigabyte. L’aumento delle dimensioni delle finestre è una parte di ciò che è necessario per il tuning TCP.
L’opzione window scale è usata solo durante il TCP 3-way handshake. Il valore di window scale rappresenta il numero di bit per spostare a sinistra il campo della dimensione della finestra a 16 bit. Il valore di window scale può essere impostato da 0 (nessuno spostamento) a 14 per ogni direzione in modo indipendente. Entrambe le parti devono inviare l’opzione nei loro segmenti SYN per abilitare il window scaling in entrambe le direzioni.
Alcuni router e firewall di pacchetti riscrivono il fattore di window scaling durante una trasmissione. Questo fa sì che i lati mittente e ricevente assumano differenti dimensioni delle finestre TCP. Il risultato è un traffico non stabile che può essere molto lento. Il problema è visibile in alcuni siti dietro un router difettoso.
TCP timestampsEdit
TCP timestamps, definito in RFC 1323 nel 1992, può aiutare TCP a determinare in quale ordine i pacchetti sono stati inviati.TCP timestamps non sono normalmente allineati al clock di sistema e iniziano a qualche valore casuale. Molti sistemi operativi incrementano il timestamp per ogni millisecondo trascorso; tuttavia la RFC afferma solo che i tick dovrebbero essere proporzionali.
Ci sono due campi timestamp:
un valore timestamp mittente a 4 byte (il mio timestamp) un valore timestamp di risposta a 4 byte (il timestamp più recente ricevuto da te).
I timestamp TCP sono usati in un algoritmo conosciuto come Protection Against Wrapped Sequence numbers, o PAWS (vedi RFC 1323 per i dettagli). Il PAWS è usato quando la finestra di ricezione attraversa il confine del wraparound del numero di sequenza. Nel caso in cui un pacchetto sia stato potenzialmente ritrasmesso, risponde alla domanda: “Questo numero di sequenza è nei primi 4 GB o nel secondo?”. E il timestamp è usato per rompere la parità.
Inoltre, l’algoritmo di rilevamento Eifel (RFC 3522) usa i timestamp TCP per determinare se le ritrasmissioni si stanno verificando perché i pacchetti sono persi o semplicemente fuori ordine.
Statistiche recenti mostrano che il livello di adozione del timestamp è stagnante, a ~40%, a causa del calo del supporto dei server Windows da Windows Server 2008.
I timestamp TCP sono abilitati per default nel kernel Linux, e disabilitati di default in Windows Server 2008, 2012 e 2016.
DataEdit fuori banda
È possibile interrompere o interrompere il flusso in coda invece di aspettare che il flusso finisca. Questo viene fatto specificando i dati come urgenti. Questo dice al programma ricevente di processarlo immediatamente, insieme al resto dei dati urgenti. Una volta finito, TCP informa l’applicazione e riprende la coda del flusso. Un esempio è quando TCP è usato per una sessione di login remoto, l’utente può inviare una sequenza di tastiera che interrompe o interrompe il programma all’altro capo. Questi segnali sono spesso necessari quando un programma sulla macchina remota non funziona correttamente. I segnali devono essere inviati senza aspettare che il programma finisca il suo trasferimento in corso.
TCP dati fuori banda non è stato progettato per l’Internet moderno. Il puntatore urgente altera solo l’elaborazione sull’host remoto e non accelera alcuna elaborazione sulla rete stessa. Quando arriva all’host remoto ci sono due interpretazioni leggermente diverse del protocollo, il che significa che solo singoli byte di dati OOB sono affidabili. Questo supponendo che sia affidabile, dato che è uno degli elementi del protocollo meno usati e tende ad essere implementato male.
Forzare la consegna dei datiModifica
Normalmente, TCP aspetta 200 ms per inviare un pacchetto completo di dati (l’algoritmo di Nagle cerca di raggruppare piccoli messaggi in un singolo pacchetto). Questa attesa crea piccoli, ma potenzialmente gravi ritardi se ripetuti costantemente durante un trasferimento di file. Per esempio, un tipico blocco di invio sarebbe di 4 KB, un tipico MSS è di 1460, quindi 2 pacchetti escono su una ethernet a 10 Mbit/s impiegando ~1.2 ms ciascuno seguito da un terzo che trasporta i rimanenti 1176 dopo una pausa di 197 ms perché TCP sta aspettando un buffer completo.
Nel caso di telnet, ogni pressione di tasti dell’utente viene riecheggiata dal server prima che l’utente possa vederlo sullo schermo. Questo ritardo diventerebbe molto fastidioso.
Impostare l’opzione socket TCP_NODELAY sovrascrive il ritardo di invio predefinito di 200 ms. I programmi applicativi usano questa opzione socket per forzare l’invio dell’output dopo aver scritto un carattere o una linea di caratteri.
L’RFC definisce il bit PSH push come “un messaggio allo stack TCP ricevente per inviare immediatamente questi dati all’applicazione ricevente”. Non c’è modo di indicarlo o controllarlo nello spazio utente usando i socket Berkeley ed è controllato solo dallo stack di protocollo.