Design degli esperimenti > Inter-rater Reliability
Che cos’è l’Inter-rater Reliability?
L’affidabilità inter-rater è il livello di accordo tra i raters o giudici. Se tutti sono d’accordo, l’IRR è 1 (o 100%) e se tutti non sono d’accordo, l’IRR è 0 (0%). Esistono diversi metodi per calcolare l’IRR, dai più semplici (ad esempio la percentuale di accordo) ai più complessi (ad esempio il Kappa di Cohen). Quale scegliete dipende in gran parte dal tipo di dati che avete e da quanti valutatori ci sono nel vostro modello.
Metodi di affidabilità tra valutatori
Accordo percentuale per due valutatori
La misura di base dell’affidabilità tra valutatori è l’accordo percentuale tra i valutatori.
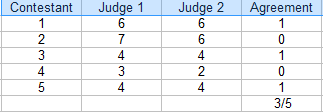
In questa competizione, i giudici hanno concordato su 3 punteggi su 5. La percentuale di accordo è 3/5 = 60%.
Per trovare la percentuale di accordo per due valutatori, una tabella (come quella sopra) è utile.
- Conta il numero di valutazioni in accordo. Nella tabella qui sopra, sono 3.
- Conta il numero totale di valutazioni. Per questo esempio, è 5.
- Dividere il totale per il numero di voti in accordo per ottenere una frazione: 3/5.
- Convertire in percentuale: 3/5 = 60%.
Il campo in cui stai lavorando determinerà il livello di accordo accettabile. Se si tratta di una competizione sportiva, si potrebbe accettare un accordo del 60% per decidere un vincitore. Tuttavia, se state guardando i dati di specialisti del cancro che decidono su un ciclo di trattamento, vorrete un accordo molto più alto – sopra il 90%. In generale, sopra il 75% è considerato accettabile per la maggior parte dei campi.
Accordo percentuale per più valutatori
Se hai più valutatori, calcola la percentuale di accordo come segue:
Step 1: Fai una tabella delle tue valutazioni. Per questo esempio, ci sono tre giudici: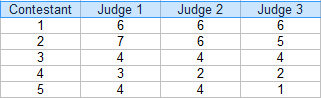
Step 2: Aggiungi ulteriori colonne per le combinazioni (coppie) di giudici. Per questo esempio, le tre coppie possibili sono: J1/J2, J1/J3 e J2/J3.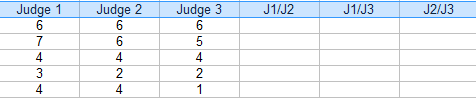
Step 3: Per ogni coppia, mettere un “1” per accordo e “0” per accordo. Per esempio, concorrente 4, giudice 1/giudice 2 non era d’accordo (0), giudice 1/giudice 3 non era d’accordo (0) e giudice 2/giudice 3 era d’accordo (1).
Step 4: Sommare gli 1 e gli 0 in una colonna di accordo:
Step 5: Trovare la media delle frazioni nella colonna Accordo.
Media = (3/3 + 0/3 + 3/3 + 1/3 + 1/3) / 5 = 0.53, o 53%.
L’affidabilità inter-rater per questo esempio è del 54%.
Svantaggi
Come potete probabilmente capire, calcolare la percentuale di accordo per più di una manciata di raters può diventare rapidamente ingombrante. Per esempio, se aveste 6 giudici, avreste 16 combinazioni di coppie da calcolare per ogni concorrente (usate il nostro calcolatore di combinazioni per capire quante coppie avreste per più giudici).
Un grande difetto di questo tipo di affidabilità inter-rater è che non tiene conto dell’accordo casuale e sopravvaluta il livello di accordo. Questa è la ragione principale per cui l’accordo percentuale non dovrebbe essere usato per il lavoro accademico (cioè dissertazioni o pubblicazioni accademiche).
Metodi alternativi
Sono stati sviluppati diversi metodi che sono più facili da calcolare (di solito sono integrati nei pacchetti software statistici) e tengono conto del caso:
- Se hai una o due coppie significative, usa la correlazione interclasse (equivalente al coefficiente di correlazione di Pearson).
- Se hai più di un paio di coppie, usa la correlazione intraclasse. Questo è uno dei metodi IRR più popolari ed è usato per due o più valutatori.
- Kappa di Cohen: comunemente usato per variabili categoriche.
- Kappa di Fleiss: simile al Kappa di Cohen, adatto quando si ha un numero costante di m valutatori campionati a caso da una popolazione di valutatori, con un campione diverso di m valutatori per ogni soggetto.
- Il coefficiente AC2 di Gwet è calcolato facilmente in Excel con l’add on di AgreeStat.com.
- L’alfa di Krippendorff è probabilmente la migliore misura dell’affidabilità inter-rater, ma è computazionalmente complessa.
Beyer, W. H. CRC Standard Mathematical Tables, 31st ed. Boca Raton, FL: CRC Press, pp. 536 e 571, 2002.
Everitt, B. S.; Skrondal, A. (2010), The Cambridge Dictionary of Statistics, Cambridge University Press.
Klein, G. (2013). L’introduzione a fumetti alla statistica. Hill & Wamg.
Vogt, W.P. (2005). Dizionario di Statistica & Metodologia: A Nontechnical Guide for the Social Sciences. SAGE.
Stephanie Glen. “Inter-rater Reliability IRR: Definition, Calculation” Da StatisticsHowTo.com: Statistica elementare per il resto di noi! https://www.statisticshowto.com/inter-rater-reliability/
——————————————————————————
Hai bisogno di aiuto per un compito a casa o per un test? Con Chegg Study, puoi ottenere soluzioni passo dopo passo alle tue domande da un esperto del settore. I tuoi primi 30 minuti con un tutor Chegg sono gratuiti!