Generalmente, per qualsiasi problema di classificazione, prevediamo il valore della classe che ha la più alta probabilità di essere la vera etichetta di classe. Tuttavia, a volte, vogliamo predire le probabilità che un’istanza di dati appartenga ad ogni etichetta di classe. Per esempio, diciamo che stiamo costruendo un modello per classificare la frutta e abbiamo tre etichette di classe: mele, arance e banane (ogni frutto è uno di questi). Per ogni frutto, vogliamo le probabilità che il frutto sia una mela, un’arancia o una banana.
Questo è molto utile per la valutazione di un modello di classificazione. Può aiutarci a capire quanto “sicuro” sia un modello nel predire un’etichetta di classe e può aiutarci a interpretare quanto sia decisivo un modello di classificazione. Generalmente, i classificatori che hanno una probabilità lineare di predire le etichette di ogni classe sono chiamati calibrati. Il problema è che non tutti i modelli di classificazione sono calibrati.
Alcuni modelli possono dare stime scadenti delle probabilità di classe e alcuni non supportano nemmeno la previsione delle probabilità.
Curve di calibrazione:
Le curve di calibrazione sono usate per valutare quanto è calibrato un classificatore, cioè come le probabilità di predire ogni etichetta di classe differiscono. L’asse x rappresenta la probabilità media prevista in ogni bin. L’asse y è il rapporto dei positivi (la proporzione di previsioni positive). La curva del modello calibrato ideale è una linea retta lineare da (0, 0) che si muove linearmente.
Tracciare le curve di calibrazione in Python3:
Per questo esempio, useremo un dataset binario. Useremo il popolare set di dati sul diabete. Potete saperne di più su questo set di dati qui.
Codice: Implementare la curva di calibrazione di una Support Vector Machine e confrontarla con la curva di un modello perfettamente calibrato.
fromsklearn.datasets importload_breast_cancer fromsklearn.svm importSVC fromsklearn.model_selection importtrain_test_split fromsklearn.calibration importcalibration_curve importmatplotlib.pyplot as plt dataset =load_breast_cancer() X =dataset.data y =dataset.target X_train, X_test, y_train, y_test =train_test_split(X, y, test_size =0.1, random_state =13) model =SVC() model.fit(X_train, y_train) prob =model.decision_function(X_test)
x, y =calibration_curve(y_test, prob, n_bins =10, normalize =True) plt.plot(, , linestyle ='--', label ='Ideally Calibrated') plt.plot(y, x, marker ='.', label ='Support Vector Classifier') leg =plt.legend(loc ='upper left') plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives') plt.show() Output:
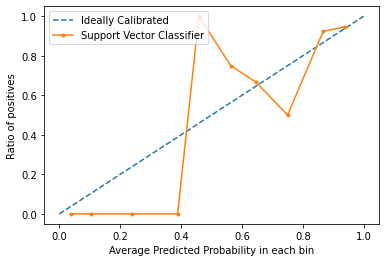
Dal grafico, possiamo vedere chiaramente che il classificatore Suppor Vector non è calibrato molto bene. Più la curva di un modello è vicina alla curva del modello perfettamente calibrato (curva tratteggiata), meglio è calibrato.
Conclusione:
Ora che sai cos’è la calibrazione in termini di Machine Learning e come tracciare una curva di calibrazione, la prossima volta che il tuo classificatore dà risultati imprevedibili e non riesci a trovare la causa, prova a tracciare la curva di calibrazione e controlla se il modello è ben calibrato.
