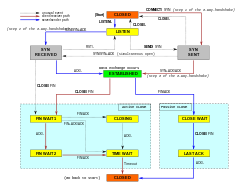
Les opérations du protocole TCP peuvent être divisées en trois phases. L’établissement de la connexion est un processus de poignée de main en plusieurs étapes qui établit une connexion avant d’entrer dans la phase de transfert de données. Une fois le transfert de données terminé, la terminaison de la connexion ferme la connexion et libère toutes les ressources allouées.
Une connexion TCP est gérée par un système d’exploitation par le biais d’une ressource qui représente le point d’extrémité local des communications, le socket Internet. Pendant la durée de vie d’une connexion TCP, le point d’extrémité local subit une série de changements d’état :
| État | Endpoint | Description |
|---|---|---|
| Serveur | En attente d’une demande de connexion de n’importe quel point de terminaison TCP distant.distant. | |
| SYN-SENT | Client | En attente d’une demande de connexion correspondante après avoir envoyé une demande de connexion. |
| Serveur | En attente d’un accusé de réception de demande de connexion de confirmation après avoir à la fois reçu et envoyé une demande de connexion. | ESTABLISHED | Serveur et client | Une connexion ouverte, les données reçues peuvent être délivrées à l’utilisateur. L’état normal pour la phase de transfert de données de la connexion. |
| FIN-WAIT-1 | Serveur et client | En attente d’une demande de fin de connexion du TCP distant, ou d’un accusé de réception de la demande de fin de connexion précédemment envoyée. |
| FIN-WAIT-2 | Serveur et client | En attente d’une demande de fin de connexion provenant du TCP distant. |
| CLOSE-WAIT | Serveur et client | En attente d’une demande de fin de connexion provenant de l’utilisateur local. |
| CLOSING | Serveur et client | En attente d’un accusé de réception de demande de fin de connexion de la part du TCP distant. |
| LAST-ACK | Serveur et client | En attente d’un accusé de réception de la demande de terminaison de connexion précédemment envoyée au TCP distant (qui inclut un accusé de réception de sa demande de terminaison de connexion). |
| TIME-WAIT | Serveur ou client | Attendant que suffisamment de temps s’écoule pour être sûr que le TCP distant a reçu l’accusé de réception de sa demande de fin de connexion. |
| CLOSED | Serveur et client | Aucun état de connexion du tout. |
Établissement de la connexionÉdit
Avant qu’un client ne tente de se connecter à un serveur, ce dernier doit d’abord se lier à un port et l’écouter pour l’ouvrir aux connexions : on appelle cela une ouverture passive. Une fois l’ouverture passive établie, un client peut établir une connexion en initiant une ouverture active à l’aide de la poignée de main à trois voies (ou 3 étapes) :
- SYN : l’ouverture active est effectuée par le client qui envoie un SYN au serveur. Le client fixe le numéro de séquence du segment à une valeur aléatoire A.
- SYN-ACK : En réponse, le serveur répond par un SYN-ACK. Le numéro d’accusé de réception est fixé à un de plus que le numéro de séquence reçu, c’est-à-dire A+1, et le numéro de séquence que le serveur choisit pour le paquet est un autre nombre aléatoire, B.
- ACK : Enfin, le client renvoie un ACK au serveur. Le numéro de séquence est fixé à la valeur de l’accusé de réception reçu, c’est-à-dire A+1, et le numéro d’accusé de réception est fixé à un de plus que le numéro de séquence reçu, c’est-à-dire B+1.
Les étapes 1 et 2 établissent et accusent réception du numéro de séquence pour une direction. Les étapes 2 et 3 établissent et acquittent le numéro de séquence pour l’autre direction. Après l’achèvement de ces étapes, le client et le serveur ont tous deux reçu des accusés de réception et une communication en duplex intégral est établie.
Résiliation de la connexion

La phase de résiliation de la connexion utilise une poignée de main à quatre voies, chaque côté de la connexion se terminant indépendamment. Lorsqu’un point d’extrémité souhaite arrêter sa moitié de la connexion, il transmet un paquet FIN, que l’autre extrémité accuse réception avec un ACK. Par conséquent, un arrêt typique nécessite une paire de segments FIN et ACK de chaque point d’extrémité TCP. Après que le côté qui a envoyé le premier FIN a répondu avec l’ACK final, il attend un délai d’attente avant de fermer définitivement la connexion, pendant lequel le port local est indisponible pour de nouvelles connexions ; cela permet d’éviter toute confusion due à la livraison de paquets retardés lors de connexions ultérieures.
Une connexion peut être « semi-ouverte », auquel cas un côté a mis fin à son extrémité, mais pas l’autre. Le côté qui a terminé ne peut plus envoyer de données dans la connexion, mais l’autre côté le peut. Le côté qui met fin à la connexion doit continuer à lire les données jusqu’à ce que l’autre côté mette également fin à la connexion.
Il est également possible de mettre fin à la connexion par une poignée de main à 3 voies, lorsque l’hôte A envoie un FIN et que l’hôte B répond avec un FIN & ACK (combine simplement 2 étapes en une seule) et que l’hôte A répond avec un ACK.
Certains systèmes d’exploitation, tels que Linux et H-UX, mettent en œuvre une séquence de fermeture semi-duplex dans la pile TCP. Si l’hôte ferme activement une connexion, tout en ayant encore des données entrantes non lues disponibles, il envoie le signal RST (perte de toute donnée reçue) au lieu de FIN. Cela garantit à une application TCP que le processus distant a lu toutes les données transmises en attendant le signal FIN, avant de fermer activement la connexion. Le processus distant ne peut pas faire la distinction entre un signal RST pour l’abandon de la connexion et la perte de données. Les deux provoquent la perte de toutes les données reçues par la pile distante.
Certaines applications utilisant le protocole de handshaking TCP d’ouverture/fermeture peuvent trouver le problème RST sur la fermeture active. A titre d’exemple :
s = connect(remote);send(s, data);close(s);
Pour un flux de programme comme celui décrit ci-dessus, une pile TCP/IP ne garantit pas que toutes les données arrivent à l’autre application si des données non lues sont arrivées à cette extrémité.
Utilisation des ressourcesModification
La plupart des implémentations allouent une entrée dans une table qui mappe une session à un processus de système d’exploitation en cours d’exécution. Comme les paquets TCP n’incluent pas d’identifiant de session, les deux extrémités identifient la session à l’aide de l’adresse et du port du client. Chaque fois qu’un paquet est reçu, l’implémentation TCP doit effectuer une recherche dans cette table pour trouver le processus de destination. Chaque entrée de la table est appelée « bloc de contrôle de transmission » ou TCB. Elle contient des informations sur les points d’extrémité (IP et port), l’état de la connexion, des données d’exécution sur les paquets échangés et des tampons pour l’envoi et la réception des données.
Le nombre de sessions côté serveur n’est limité que par la mémoire et peut croître au fur et à mesure de l’arrivée de nouvelles connexions, mais le client doit allouer un port aléatoire avant d’envoyer le premier SYN au serveur. Ce port reste alloué pendant toute la conversation, et limite effectivement le nombre de connexions sortantes de chacune des adresses IP du client. Si une application ne parvient pas à fermer correctement les connexions non demandées, un client peut manquer de ressources et devenir incapable d’établir de nouvelles connexions TCP, même à partir d’autres applications.
Les deux points d’extrémité doivent également allouer de l’espace pour les paquets non acquittés et les données reçues (mais non lues).
Transfert de donnéesModification
Le protocole de contrôle de transmission diffère par plusieurs caractéristiques clés du protocole de datagramme utilisateur :
- Transfert de données ordonné : l’hôte de destination réorganise les segments selon un numéro de séquence
- Retransmission des paquets perdus : tout flux cumulatif n’ayant pas fait l’objet d’un accusé de réception est retransmis
- Transfert de données sans erreur
- Contrôle de flux : limite le taux auquel un émetteur transfère des données pour garantir une livraison fiable. Le récepteur indique continuellement à l’expéditeur la quantité de données qu’il peut recevoir (contrôlée par la fenêtre glissante). Lorsque le tampon de l’hôte récepteur se remplit, l’accusé de réception suivant contient un 0 dans la taille de la fenêtre, pour arrêter le transfert et permettre le traitement des données dans le tampon.
- Contrôle de congestion
Transmission fiableEdit
TCP utilise un numéro de séquence pour identifier chaque octet de données. Le numéro de séquence identifie l’ordre des octets envoyés par chaque ordinateur afin que les données puissent être reconstituées dans l’ordre, indépendamment de tout réordonnancement des paquets, ou de toute perte de paquets qui pourrait se produire pendant la transmission. Le numéro de séquence du premier octet est choisi par l’émetteur pour le premier paquet, qui est marqué SYN. Ce numéro peut être arbitraire, et devrait, en fait, être imprévisible pour se défendre contre les attaques de prédiction de séquence TCP.
Les accusés de réception (ACK) sont envoyés avec un numéro de séquence par le récepteur de données pour indiquer à l’émetteur que les données ont été reçues jusqu’à l’octet spécifié. Les ACKs n’impliquent pas que les données ont été livrées à l’application. Ils signifient simplement qu’il incombe maintenant au récepteur de livrer les données.
La fiabilité est assurée par l’expéditeur qui détecte les données perdues et les retransmet. Le protocole TCP utilise deux techniques principales pour identifier les pertes. Le délai de retransmission (abrégé en RTO) et les acquittements cumulatifs dupliqués (DupAcks).
Retransmission basée sur DupackEdit
Si un seul segment (disons le segment 100) dans un flux est perdu, alors le récepteur ne peut pas acquitter les paquets au-dessus du n°. 100 car il utilise des ACKs cumulatifs. Par conséquent, le récepteur acquitte à nouveau le paquet 99 à la réception d’un autre paquet de données. Cet acquittement en double est utilisé comme un signal de perte de paquets. C’est-à-dire que si l’expéditeur reçoit trois acquittements en double, il retransmet le dernier paquet non acquitté. Un seuil de trois est utilisé parce que le réseau peut réorganiser les segments, ce qui entraîne des accusés de réception en double. Il a été démontré que ce seuil permet d’éviter les retransmissions intempestives dues au réordonnancement. Parfois, des accusés de réception sélectifs (SACK) sont utilisés pour fournir un retour d’information explicite sur les segments qui ont été reçus. Cela améliore considérablement la capacité de TCP à retransmettre les bons segments.
Retransmission basée sur le délai d’attenteModification
Lorsqu’un expéditeur transmet un segment, il initialise un temporisateur avec une estimation prudente de l’heure d’arrivée de l’accusé de réception. Le segment est retransmis si le temporisateur expire, avec un nouveau seuil de temporisation de deux fois la valeur précédente, ce qui entraîne un comportement de backoff exponentiel. Typiquement, la valeur initiale du timer est RTT lissé + max ( G , 4 × variation du RTT ) {\displaystyle {\text{smoothed RTT}}+\max(G,4\times {\text{RTT variation}})}.

, où G {\displaystyle G}

est la granularité de l’horloge. Cela permet de se prémunir contre un trafic de transmission excessif dû à des acteurs défaillants ou malveillants, tels que les attaquants en déni de service de type man-in-the-middle.
Détection d’erreurModification
Les numéros de séquence permettent aux récepteurs d’écarter les paquets en double et de séquencer correctement les paquets réordonnés. Les accusés de réception permettent aux expéditeurs de déterminer quand retransmettre les paquets perdus.
Pour assurer l’exactitude, un champ de somme de contrôle est inclus ; voir la section sur le calcul de la somme de contrôle pour plus de détails sur la somme de contrôle. La somme de contrôle TCP est une vérification faible par rapport aux normes modernes. Les couches de liaison de données avec des taux d’erreurs binaires élevés peuvent nécessiter des capacités supplémentaires de correction/détection des erreurs de liaison. La faiblesse de la somme de contrôle est partiellement compensée par l’utilisation courante d’un CRC ou d’un meilleur contrôle d’intégrité au niveau de la couche 2, sous TCP et IP, tel qu’il est utilisé dans PPP ou la trame Ethernet. Toutefois, cela ne signifie pas que la somme de contrôle TCP de 16 bits est redondante : il est remarquable que l’introduction d’erreurs dans les paquets entre les sauts protégés par le CRC soit courante, mais la somme de contrôle TCP de 16 bits de bout en bout permet de détecter la plupart de ces erreurs simples. C’est le principe de bout en bout à l’œuvre.
Contrôle de fluxModifier
Le TCP utilise un protocole de contrôle de flux de bout en bout pour éviter que l’expéditeur envoie des données trop rapidement pour que le récepteur TCP puisse les recevoir et les traiter de manière fiable. Disposer d’un mécanisme de contrôle de flux est essentiel dans un environnement où communiquent des machines ayant des vitesses de réseau diverses. Par exemple, si un PC envoie des données à un smartphone qui traite lentement les données reçues, le smartphone doit réguler le flux de données pour ne pas être submergé.
TCP utilise un protocole de contrôle de flux à fenêtre glissante. Dans chaque segment TCP, le récepteur spécifie dans le champ de la fenêtre de réception la quantité de données reçues en plus (en octets) qu’il est prêt à mettre en mémoire tampon pour la connexion. L’hôte émetteur ne peut envoyer que jusqu’à cette quantité de données avant de devoir attendre un accusé de réception et une mise à jour de la fenêtre de la part de l’hôte récepteur.

Lorsqu’un récepteur annonce une taille de fenêtre de 0, l’émetteur arrête d’envoyer des données et démarre le temporisateur persist. Le temporisateur persist est utilisé pour protéger TCP d’une situation de blocage qui pourrait survenir si une mise à jour ultérieure de la taille de la fenêtre du récepteur est perdue, et que l’expéditeur ne peut plus envoyer de données jusqu’à la réception d’une nouvelle mise à jour de la taille de la fenêtre du récepteur. Lorsque le temporisateur persist expire, l’expéditeur TCP tente de récupérer en envoyant un petit paquet afin que le récepteur réponde en envoyant un autre accusé de réception contenant la nouvelle taille de fenêtre.
Si un récepteur traite les données entrantes par petits incréments, il peut annoncer à plusieurs reprises une petite fenêtre de réception. C’est ce qu’on appelle le syndrome de la fenêtre idiote, car il est inefficace d’envoyer seulement quelques octets de données dans un segment TCP, compte tenu de l’overhead relativement important de l’en-tête TCP.
Contrôle de congestionModifier
Le dernier aspect principal de TCP est le contrôle de congestion. TCP utilise un certain nombre de mécanismes pour atteindre des performances élevées et éviter l’effondrement de la congestion, où les performances du réseau peuvent chuter de plusieurs ordres de grandeur. Ces mécanismes contrôlent le taux de données entrant dans le réseau, en maintenant le flux de données en dessous d’un taux qui déclencherait l’effondrement. Ils produisent également une allocation équitable approximativement max-min entre les flux.
Les accusés de réception des données envoyées, ou l’absence d’accusés de réception, sont utilisés par les expéditeurs pour déduire les conditions du réseau entre l’expéditeur et le récepteur TCP. Couplés à des temporisateurs, les émetteurs et les récepteurs TCP peuvent modifier le comportement du flux de données. On parle plus généralement de contrôle de la congestion et/ou d’évitement de la congestion du réseau.
Les implémentations modernes de TCP contiennent quatre algorithmes imbriqués : démarrage lent, évitement de la congestion, retransmission rapide et récupération rapide (RFC 5681).
En outre, les expéditeurs emploient un délai de retransmission (RTO) qui est basé sur le temps aller-retour (ou RTT) estimé entre l’expéditeur et le récepteur, ainsi que sur la variance de ce temps aller-retour. Le comportement de ce temporisateur est spécifié dans la RFC 6298. Il existe des subtilités dans l’estimation du RTT. Par exemple, les expéditeurs doivent être prudents lorsqu’ils calculent les échantillons de RTT pour les paquets retransmis ; ils utilisent généralement l’algorithme de Karn ou les timestamps TCP (voir RFC 1323). Ces échantillons individuels de RTT sont ensuite moyennés dans le temps pour créer un Smoothed Round Trip Time (SRTT) à l’aide de l’algorithme de Jacobson. C’est cette valeur SRTT qui est finalement utilisée comme estimation du temps d’aller-retour.
L’amélioration de TCP pour gérer de manière fiable les pertes, minimiser les erreurs, gérer la congestion et aller vite dans les environnements à très haut débit sont des domaines de recherche et de développement de normes en cours. Par conséquent, il existe un certain nombre de variations d’algorithmes d’évitement de la congestion TCP.
Taille maximale du segmentModifier
La taille maximale du segment (MSS) est la plus grande quantité de données, spécifiée en octets, que TCP est prêt à recevoir dans un seul segment. Pour de meilleures performances, la MSS doit être définie suffisamment petite pour éviter la fragmentation IP, qui peut entraîner la perte de paquets et des retransmissions excessives. Pour tenter d’y parvenir, le MSS est généralement annoncé par chaque partie à l’aide de l’option MSS lors de l’établissement de la connexion TCP, auquel cas il est dérivé de la taille maximale de l’unité de transmission (MTU) de la couche liaison de données des réseaux auxquels l’émetteur et le récepteur sont directement rattachés. En outre, les expéditeurs TCP peuvent utiliser la découverte du MTU de chemin pour déduire le MTU minimum le long du chemin réseau entre l’expéditeur et le récepteur, et l’utiliser pour ajuster dynamiquement le MSS afin d’éviter la fragmentation IP au sein du réseau.
L’annonce du MSS est aussi souvent appelée « négociation du MSS ». À proprement parler, le MSS n’est pas « négocié » entre l’émetteur et le récepteur, car cela impliquerait que l’émetteur et le récepteur négocient et conviennent d’un MSS unique et unifié qui s’applique à toutes les communications dans les deux sens de la connexion. En fait, deux valeurs de MSS complètement indépendantes sont autorisées pour les deux directions du flux de données dans une connexion TCP. Cette situation peut se produire, par exemple, si l’un des périphériques participant à une connexion dispose d’une quantité extrêmement limitée de mémoire réservée (peut-être même inférieure à la MTU globale du chemin découvert) pour traiter les segments TCP entrants.
Acquittements sélectifsModifier
S’appuyer purement sur le schéma d’acquittement cumulatif employé par le protocole TCP original peut conduire à des inefficacités lorsque des paquets sont perdus. Par exemple, supposons que des octets portant le numéro de séquence 1 000 à 10 999 soient envoyés dans 10 segments TCP différents de taille égale, et que le deuxième segment (numéros de séquence 2 000 à 2 999) soit perdu pendant la transmission. Dans un protocole d’accusé de réception cumulatif pur, le récepteur ne peut envoyer qu’une valeur ACK cumulative de 2 000 (le numéro de séquence suivant immédiatement le dernier numéro de séquence des données reçues) et ne peut pas dire qu’il a reçu les octets 3 000 à 10 999 avec succès. Ainsi, l’expéditeur peut alors devoir renvoyer toutes les données commençant par le numéro de séquence 2 000.
Pour pallier ce problème, TCP emploie l’option d’acquittement sélectif (SACK), définie en 1996 dans le RFC 2018, qui permet au récepteur d’acquitter les blocs discontinus de paquets qui ont été reçus correctement, en plus du numéro de séquence suivant immédiatement le dernier numéro de séquence du dernier octet contigu reçu successivement, comme dans l’acquittement TCP de base. L’accusé de réception peut spécifier un certain nombre de blocs SACK, où chaque bloc SACK est transmis par le bord gauche du bloc (le premier numéro de séquence du bloc) et le bord droit du bloc (le numéro de séquence suivant immédiatement le dernier numéro de séquence du bloc), un bloc étant une plage contiguë que le récepteur a correctement reçue. Dans l’exemple ci-dessus, le récepteur enverrait un segment ACK avec une valeur ACK cumulative de 2 000 et un en-tête d’option SACK avec les numéros de séquence 3 000 et 11 000. L’expéditeur ne retransmettrait en conséquence que le deuxième segment avec les numéros de séquence 2 000 à 2 999.
Un expéditeur TCP peut interpréter une livraison de segment hors ordre comme un segment perdu. S’il le fait, l’expéditeur TCP retransmet le segment précédent le paquet hors ordre et ralentit son taux de livraison de données pour cette connexion. L’option duplicate-SACK, une extension de l’option SACK qui a été définie en mai 2000 dans le RFC 2883, résout ce problème. Le récepteur TCP envoie un D-ACK pour indiquer qu’aucun segment n’a été perdu, et l’émetteur TCP peut alors rétablir le taux de transmission plus élevé.
L’option SACK n’est pas obligatoire, et n’entre en fonction que si les deux parties la supportent. Elle est négociée lorsqu’une connexion est établie. SACK utilise une option de l’en-tête TCP (voir la structure du segment TCP pour plus de détails). L’utilisation de SACK s’est généralisée – toutes les piles TCP populaires le supportent. L’accusé de réception sélectif est également utilisé dans le protocole de transmission de contrôle de flux (SCTP).
Mise à l’échelle de la fenêtreModifier
Pour une utilisation plus efficace des réseaux à large bande passante, une taille de fenêtre TCP plus importante peut être utilisée. Le champ de taille de la fenêtre TCP contrôle le flux de données et sa valeur est limitée entre 2 et 65 535 octets.
Comme le champ de taille ne peut pas être étendu, un facteur d’échelle est utilisé. L’option d’échelle de la fenêtre TCP, définie dans la RFC 1323, est une option utilisée pour augmenter la taille maximale de la fenêtre de 65 535 octets à 1 gigaoctet. La mise à l’échelle vers des tailles de fenêtre plus importantes fait partie de ce qui est nécessaire pour le tuning TCP.
L’option de mise à l’échelle de la fenêtre n’est utilisée que pendant la poignée de main TCP à trois voies. La valeur de l’échelle de la fenêtre représente le nombre de bits pour décaler à gauche le champ de taille de fenêtre de 16 bits. La valeur de l’échelle de fenêtre peut être définie de 0 (aucun décalage) à 14 pour chaque direction indépendamment. Les deux côtés doivent envoyer l’option dans leurs segments SYN pour activer le décalage de la fenêtre dans l’une ou l’autre direction.
Certains routeurs et pare-feu de paquets réécrivent le facteur de décalage de la fenêtre pendant une transmission. Cela amène les côtés émetteur et récepteur à assumer des tailles de fenêtre TCP différentes. Il en résulte un trafic non stable qui peut être très lent. Le problème est visible sur certains sites derrière un routeur défectueux.
TCP timestampsEdit
Les timestamps TCP, définis dans le RFC 1323 en 1992, peuvent aider TCP à déterminer dans quel ordre les paquets ont été envoyés.Les timestamps TCP ne sont normalement pas alignés sur l’horloge système et commencent à une valeur aléatoire. De nombreux systèmes d’exploitation incrémentent l’horodatage pour chaque milliseconde écoulée ; cependant, la RFC indique seulement que les ticks doivent être proportionnels.
Il existe deux champs d’horodatage :
une valeur d’horodatage d’expéditeur de 4 octets (mon horodatage) une valeur d’horodatage de réponse d’écho de 4 octets (l’horodatage le plus récent reçu de vous).
Les horodatages TCP sont utilisés dans un algorithme connu sous le nom de Protection Against Wrapped Sequence numbers, ou PAWS (voir RFC 1323 pour plus de détails). Le PAWS est utilisé lorsque la fenêtre de réception franchit la limite du wraparound des numéros de séquence. Dans le cas où un paquet a été potentiellement retransmis, il répond à la question suivante : « Ce numéro de séquence est-il dans les 4 premiers Go ou dans le second ? ». Et l’horodatage est utilisé pour briser l’égalité.
Aussi, l’algorithme de détection Eifel (RFC 3522) utilise les horodatages TCP pour déterminer si les retransmissions se produisent parce que les paquets sont perdus ou simplement hors de l’ordre.
Des statistiques récentes montrent que le niveau d’adoption des horodatages a stagné, à ~40%, en raison de l’abandon de la prise en charge par le serveur Windows depuis Windows Server 2008.
Les horodatages TCP sont activés par défaut Dans le noyau Linux…, et désactivés par défaut dans Windows Server 2008, 2012 et 2016.
DataEdit hors bande
Il est possible d’interrompre ou d’abandonner le flux en file d’attente au lieu d’attendre que le flux se termine. Cela se fait en spécifiant les données comme urgentes. Cela indique au programme récepteur de la traiter immédiatement, avec le reste des données urgentes. Une fois le traitement terminé, TCP en informe l’application et retourne à la file d’attente du flux. Par exemple, lorsque TCP est utilisé pour une session de connexion à distance, l’utilisateur peut envoyer une séquence de clavier qui interrompt ou abandonne le programme à l’autre bout. Ces signaux sont le plus souvent nécessaires lorsqu’un programme de la machine distante ne fonctionne pas correctement. Les signaux doivent être envoyés sans attendre que le programme termine son transfert en cours.
Les données hors bande deTCP n’ont pas été conçues pour l’Internet moderne. Le pointeur urgent ne fait que modifier le traitement sur l’hôte distant et n’accélère aucun traitement sur le réseau lui-même. Lorsqu’elles arrivent sur l’hôte distant, il existe deux interprétations légèrement différentes du protocole, ce qui signifie que seuls les octets uniques de données OOB sont fiables. C’est en supposant qu’elles soient fiables tout court, car c’est l’un des éléments du protocole les moins utilisés et il a tendance à être mal implémenté.
Forcer la livraison des donnéesModification
Normalement, TCP attend 200 ms pour qu’un paquet complet de données soit envoyé (l’algorithme de Nagle essaie de regrouper les petits messages en un seul paquet). Cette attente crée des retards minimes, mais potentiellement graves s’ils sont répétés constamment pendant un transfert de fichiers. Par exemple, un bloc d’envoi typique serait de 4 Ko, un MSS typique est de 1460, donc 2 paquets sortent sur un ethernet 10 Mbit/s en prenant ~1,2 ms chacun, suivis d’un troisième transportant les 1176 restants après une pause de 197 ms parce que TCP attend un tampon plein.
Dans le cas de telnet, chaque frappe de l’utilisateur est renvoyée par le serveur avant que l’utilisateur puisse la voir sur l’écran. Ce délai deviendrait très gênant.
Définir l’option de socket TCP_NODELAY permet de remplacer le délai d’envoi de 200 ms par défaut. Les programmes d’application utilisent cette option socket pour forcer l’envoi de la sortie après l’écriture d’un caractère ou d’une ligne de caractères.
Le RFC définit le bit push PSH comme « un message à la pile TCP réceptrice pour envoyer ces données immédiatement vers le haut à l’application réceptrice ». Il n’y a aucun moyen de l’indiquer ou de le contrôler dans l’espace utilisateur en utilisant les sockets de Berkeley et il est contrôlé par la pile de protocole uniquement.
.