En général, pour tout problème de classification, nous prédisons la valeur de classe qui a la plus grande probabilité d’être la véritable étiquette de classe. Cependant, parfois, nous voulons prédire les probabilités d’une instance de données appartenant à chaque étiquette de classe. Par exemple, supposons que nous construisions un modèle pour classer les fruits et que nous ayons trois étiquettes de classe : pommes, oranges et bananes (chaque fruit est l’une de ces étiquettes). Pour tout fruit, nous voulons les probabilités que le fruit soit une pomme, une orange ou une banane.
Ceci est très utile pour l’évaluation d’un modèle de classification. Il peut nous aider à comprendre à quel point un modèle est » sûr » tout en prédisant une étiquette de classe et peut nous aider à interpréter à quel point un modèle de classification est décisif. En général, les classifieurs qui ont une probabilité linéaire de prédire les étiquettes de chaque classe sont dits calibrés. Le problème est que tous les modèles de classification ne sont pas calibrés.
Certains modèles peuvent donner de mauvaises estimations des probabilités de classe et certains ne supportent même pas la prédiction de probabilité.
Courbes de calibrage :
Les courbes de calibrage sont utilisées pour évaluer le degré de calibrage d’un classificateur, c’est-à-dire la différence entre les probabilités de prédiction de chaque étiquette de classe. L’axe des x représente la probabilité moyenne prédite dans chaque bin. L’axe des y est le ratio de positifs (la proportion de prédictions positives). La courbe du modèle calibré idéal est une ligne droite linéaire de (0, 0) se déplaçant linéairement.
Tracer des courbes de calibrage en Python3 :
Pour cet exemple, nous allons utiliser un ensemble de données binaires. Nous utiliserons le populaire jeu de données sur le diabète. Vous pouvez en savoir plus sur ce jeu de données ici.
Code : Implémenter la courbe de calibration d’un Support Vector Machine et la comparer avec la courbe d’un modèle parfaitement calibré.
from
sklearn.datasets importload_breast_cancer
fromsklearn.svm importSVC fromsklearn.model_selection importtrain_test_split fromsklearn.calibration importcalibration_curve importmatplotlib.pyplot as plt dataset
=load_breast_cancer()
X =dataset.data
y =dataset.target X_train, X_test, y_train, y_test =train_test_split(X, y,
test_size =0.1, random_state =13) =SVC()
model.fit(X_train, y_train)
prob =model.decision_function(X_test) x, y =calibration_curve(y_test, prob, n_bins =10, normalize =True)
plt.plot(, , linestyle ='--', label ='Ideally Calibrated')
plt.plot(y, x, marker ='.', label ='Support Vector Classifier') leg =plt.legend(loc ='upper left') plt.xlabel('Average Predicted Probability in each bin') plt.ylabel('Ratio of positives') plt.show() Sortie :
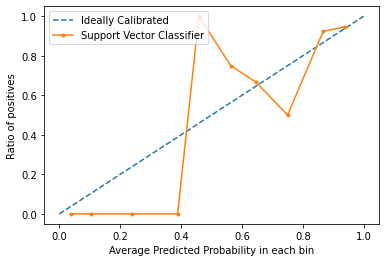
D’après le graphique, on voit clairement que le classificateur Suppor Vector n’est ni très bien calibré. Plus la courbe d’un modèle est proche de la courbe du modèle parfaitement calibré (courbe en pointillés), plus il est bien calibré.
Conclusion :
Maintenant que vous savez ce qu’est la calibration en termes de Machine Learning et comment tracer une courbe de calibration, la prochaine fois que votre classificateur donne des résultats imprévisibles et que vous ne trouvez pas la cause, essayez de tracer la courbe de calibration et vérifiez si le modèle est bien calibré.
