Design of Experiments > Fiabilité inter-juges
Qu’est-ce que la fiabilité inter-juges ?
La fiabilité inter-évaluateurs est le niveau d’accord entre les évaluateurs ou les juges. Si tout le monde est d’accord, le TRI est égal à 1 (ou 100%) et si tout le monde n’est pas d’accord, le TRI est égal à 0 (0%). Il existe plusieurs méthodes pour calculer le TRI, des plus simples (par exemple, le pourcentage d’accord) aux plus complexes (par exemple, le Kappa de Cohen). Celle que vous choisirez dépend en grande partie du type de données dont vous disposez et du nombre d’évaluateurs dans votre modèle.
Méthodes de fiabilité inter-évaluateurs
Pourcentage d’accord pour deux évaluateurs
La mesure de base de la fiabilité inter-évaluateurs est un pourcentage d’accord entre les évaluateurs.
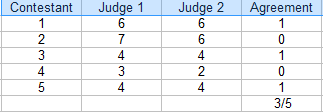
Dans ce concours, les juges se sont accordés sur 3 notes sur 5. Le pourcentage d’accord est de 3/5 = 60 %.
Pour trouver le pourcentage d’accord pour deux évaluateurs, un tableau (comme celui ci-dessus) est utile.
- Compter le nombre de notes en accord. Dans le tableau ci-dessus, c’est 3.
- Compter le nombre total de notations. Pour cet exemple, c’est 5.
- Diviser le total par le nombre en accord pour obtenir une fraction : 3/5.
- Converti en pourcentage : 3/5 = 60%.
Le domaine dans lequel vous travaillez déterminera le niveau d’accord acceptable. S’il s’agit d’une compétition sportive, vous pourriez accepter un accord de 60 % des évaluateurs pour désigner un gagnant. Cependant, si vous examinez les données de spécialistes du cancer décidant d’un traitement, vous voudrez un accord beaucoup plus élevé – supérieur à 90 %. En général, un taux supérieur à 75 % est considéré comme acceptable pour la plupart des domaines.
Pourcentage d’accord pour plusieurs évaluateurs
Si vous avez plusieurs évaluateurs, calculez le pourcentage d’accord comme suit :
Étape 1 : faites un tableau de vos évaluations. Pour cet exemple, il y a trois juges: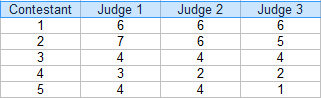
Étape 2 : Ajoutez des colonnes supplémentaires pour les combinaisons(paires) de juges. Pour cet exemple, les trois paires possibles sont : J1/J2, J1/J3 et J2/J3.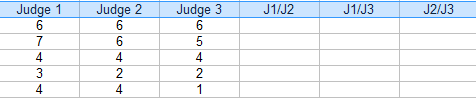
Étape 3 : Pour chaque paire, mettez un « 1 » pour accord et un « 0 » pour accord. Par exemple, le concurrent 4, le juge 1/juge 2 n’est pas d’accord (0), le juge 1/juge 3 n’est pas d’accord (0) et le juge 2 / juge 3 est d’accord (1).
Étape 4 : additionner les 1 et les 0 d’une colonne Accord :
Étape 5 : Trouver la moyenne des fractions de la colonne Accord.
Moyenne = (3/3 + 0/3 + 3/3 + 1/3 + 1/3) / 5 = 0,53, soit 53 %.
La fiabilité inter-évaluateurs pour cet exemple est de 54 %.
Inconvénients
Comme vous pouvez probablement le dire, le calcul des pourcentages d’accord pour plus d’une poignée d’évaluateurs peut rapidement devenir encombrant. Par exemple, si vous aviez 6 juges, vous auriez 16 combinaisons de paires à calculer pour chaque candidat (utilisez notre calculateur de combinaisons pour savoir combien de paires vous obtiendriez pour plusieurs juges).
Un défaut majeur de ce type de fiabilité inter-juges est qu’il ne tient pas compte de l’accord fortuit et surestime le niveau d’accord. C’est la principale raison pour laquelle l’accord en pourcentage ne devrait pas être utilisé pour les travaux universitaires (c’est-à-dire les dissertations ou les publications universitaires).
Méthodes alternatives
Plusieurs méthodes ont été développées, plus faciles à calculer (elles sont généralement intégrées dans les progiciels statistiques) et tenant compte du hasard :
- Si vous avez une ou deux paires significatives, utilisez la corrélation interclasse (équivalente au coefficient de corrélation de Pearson).
- Si vous avez plus de deux paires, utilisez la corrélation intraclasse. C’est l’une des méthodes de TRI les plus populaires et elle est utilisée pour deux évaluateurs ou plus.
- Kappa de Cohen : couramment utilisé pour les variables catégorielles.
- Kappa de Fleiss : similaire au Kappa de Cohen, adapté lorsque vous avez un nombre constant de m évaluateurs échantillonnés aléatoirement à partir d’une population d’évaluateurs, avec un échantillon différent de m codeurs évaluant chaque sujet.
- Le coefficient AC2 de Gwet se calcule facilement dans Excel avec le module complémentaire AgreeStat.com.
- L’Alpha de Krippendorff est sans doute la meilleure mesure de la fiabilité inter-juges, mais il est complexe à calculer.
Beyer, W. H. CRC Standard Mathematical Tables, 31st ed. Boca Raton, FL : CRC Press, p. 536 et 571, 2002.
Everitt, B. S. ; Skrondal, A. (2010), The Cambridge Dictionary of Statistics, Cambridge University Press.
Klein, G. (2013). L’introduction cartoonesque à la statistique. Hill & Wamg.
Vogt, W.P. (2005). Dictionnaire de la statistique & Méthodologie : Un guide non technique pour les sciences sociales. SAGE.
Stephanie Glen. « Inter-rater Reliability IRR : Definition, Calculation » De StatisticsHowTo.com : Des statistiques élémentaires pour le reste d’entre nous ! https://www.statisticshowto.com/inter-rater-reliability/
——————————————————————————
Vous avez besoin d’aide pour un devoir ou une question de test ? Avec Chegg Study, vous pouvez obtenir des solutions étape par étape à vos questions de la part d’un expert dans le domaine. Vos 30 premières minutes avec un tuteur Chegg sont gratuites !