Le module de journalisation intégré de Python est conçu pour vous donner une visibilité critique sur vos applications avec une configuration minimale. Que vous commenciez à utiliser le module de journalisation de Python ou que vous l’utilisiez déjà, ce guide vous montrera comment configurer ce module pour enregistrer toutes les données dont vous avez besoin, les acheminer vers les destinations souhaitées et centraliser vos journaux pour obtenir des informations plus approfondies sur vos applications Python. Dans ce post, nous allons vous montrer comment :
- Personnaliser le niveau de priorité et la destination de vos logs
- Configurer une configuration personnalisée qui implique plusieurs loggers et destinations
- Intégrer la gestion des exceptions et les traces dans vos logs
- Formater vos logs en JSON et les centraliser pour un dépannage plus efficace
.
Bases du module de journalisation de Python
Le module logging est inclus dans la bibliothèque standard de Python, ce qui signifie que vous pouvez commencer à l’utiliser sans rien installer. La méthode basicConfig() du module de journalisation est le moyen le plus rapide de configurer le comportement souhaité de votre logger. Cependant, la documentation Python recommande de créer un logger pour chaque module de votre application – et il peut être difficile de configurer un logger par module en utilisant basicConfig() seul. Par conséquent, la plupart des applications (y compris les frameworks web comme Django) utilisent automatiquement une configuration de journalisation basée sur des fichiers ou des dictionnaires à la place. Si vous souhaitez commencer avec l’une de ces méthodes, nous vous recommandons de passer directement à cette section.
Trois des principaux paramètres de basicConfig() sont :
- niveau : le niveau de priorité minimal des messages à journaliser. Par ordre de gravité croissante, les niveaux de journalisation disponibles sont : DEBUG, INFO, WARNING, ERROR et CRITICAL. Par défaut, le niveau est défini sur WARNING, ce qui signifie que le module de journalisation de Python filtrera tous les messages DEBUG ou INFO.
- handler : détermine où acheminer vos journaux. Sauf indication contraire de votre part, la bibliothèque de journalisation utilisera un
StreamHandlerpour diriger les messages de journalisation verssys.stderr(généralement la console). - format : par défaut, la bibliothèque de journalisation enregistrera les messages dans le format suivant :
<LEVEL>:<LOGGER_NAME>:<MESSAGE>. Dans la section suivante, nous vous montrerons comment le personnaliser pour inclure des horodatages et d’autres informations utiles pour le dépannage.
Puisque le module de journalisation ne capture par défaut que les journaux WARNING et de plus haut niveau, il se peut que vous manquiez de visibilité sur les journaux de moindre priorité qui peuvent être utiles pour mener une analyse des causes profondes. Le module de journalisation diffuse également les journaux sur la console au lieu de les annexer à un fichier. Plutôt que d’utiliser une StreamHandler ou une SocketHandler pour diffuser les journaux directement à la console ou à un service externe sur le réseau, vous devriez utiliser une FileHandler pour enregistrer dans un ou plusieurs fichiers sur le disque.
L’un des principaux avantages de la journalisation vers un fichier est que votre application n’a pas besoin de tenir compte de la possibilité de rencontrer des erreurs liées au réseau lors de la diffusion des journaux vers une destination externe. Si elle rencontre des problèmes lors du streaming des journaux sur le réseau, vous ne perdrez pas l’accès à ces journaux, puisqu’ils seront stockés localement sur chaque serveur. La journalisation vers un fichier vous permet également de créer une configuration de journalisation plus personnalisée, où vous pouvez acheminer différents types de journaux vers des fichiers distincts, et suivre et centraliser ces fichiers avec un service de surveillance des journaux.
Dans la section suivante, nous vous montrerons comment il est facile de personnaliser basicConfig() pour journaliser les messages de moindre priorité et les diriger vers un fichier sur le disque.
Un exemple de basicConfig()
L’exemple suivant utilise basicConfig() pour configurer une application afin de consigner les messages DEBUG et de niveau supérieur dans un fichier sur le disque (myapp.log). Il indique également que les journaux doivent suivre un format qui inclut l’horodatage et le niveau de gravité du journal :
import loggingdef word_count(myfile): logging.basicConfig(level=logging.DEBUG, filename='myapp.log', format='%(asctime)s %(levelname)s:%(message)s') try: # count the number of words in a file and log the result with open(myfile, 'r') as f: file_data = f.read() words = file_data.split(" ") num_words = len(words) logging.debug("this file has %d words", num_words) return num_words except OSError as e: logging.error("error reading the file")Si vous exécutez le code sur un fichier accessible (par exemple, monfichier.txt) suivi d’un fichier inaccessible (par exemple, nonexistentfile.txt), il ajoutera les journaux suivants au fichier myapp.log file:
2019-03-27 10:49:00,979 DEBUG:this file has 44 words2019-03-27 10:49:00,979 ERROR:error reading the fileGrâce à la nouvelle configuration basicConfig(), les journaux de niveau DEBUG ne sont plus filtrés, et les journaux suivent un format personnalisé qui inclut les attributs suivants:
-
%(asctime)s: affiche la date et l’heure du journal, en heure locale -
%(levelname)s: le niveau de journalisation du message -
%(message)s: le message
Voir la documentation pour des informations sur les attributs que vous pouvez inclure dans le format de chaque enregistrement de journal. Dans l’exemple ci-dessus, un message d’erreur a été enregistré, mais il n’incluait aucune information de traçage des exceptions, ce qui rendait difficile la détermination de la source du problème. Dans une section ultérieure de ce post, nous vous montrerons comment journaliser le retour de trace complet lorsqu’une exception se produit.
Digger plus profondément dans la bibliothèque de journalisation de Python
Nous avons couvert les bases de basicConfig(), mais comme mentionné précédemment, la plupart des applications bénéficieront de la mise en œuvre d’une configuration de logger par module. Au fur et à mesure que votre application évolue, vous aurez besoin d’un moyen plus robuste et évolutif de configurer chaque logger spécifique au module – et de vous assurer que vous capturez le nom du logger dans le cadre de chaque log. Dans cette section, nous allons explorer comment :
- configurer plusieurs enregistreurs et capturer automatiquement le nom de l’enregistreur
- utiliser
fileConfig()pour mettre en œuvre des options de formatage et de routage personnalisées - capturer les tracebacks et exceptions non capturées
Configurer plusieurs loggers et capturer le nom du logger
Pour suivre la meilleure pratique consistant à créer un nouveau logger pour chaque module de votre application, utilisez la méthode intégrée de la bibliothèque de journalisation getLogger() pour définir dynamiquement le nom du logger afin de correspondre au nom de votre module :
logger = logging.getLogger(__name__)Cette getLogger() méthode définit le nom du logger à __name__, qui correspond au nom pleinement qualifié du module à partir duquel cette méthode est appelée. Cela vous permet de voir exactement quel module de votre application a généré chaque message de journal, afin que vous puissiez interpréter vos journaux plus clairement.
Par exemple, si votre application comprend un module lowermodule.py qui est appelé à partir d’un autre module, uppermodule.py, la méthode getLogger() définira le nom du logger pour correspondre au module associé. Une fois que vous aurez modifié le format de votre journal pour inclure le nom du logger (%(name)s), vous verrez cette information dans chaque message du journal. Vous pouvez définir le logger au sein de chaque module comme suit :
# lowermodule.pyimport logginglogging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s')logger = logging.getLogger(__name__)def word_count(myfile): try: with open(myfile, 'r') as f: file_data = f.read() words = file_data.split(" ") final_word_count = len(words) logger.info("this file has %d words", final_word_count) return final_word_count except OSError as e: logger.error("error reading the file")# uppermodule.pyimport loggingimport lowermodule logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s')logger = logging.getLogger(__name__)def record_word_count(myfile): logger.info("starting the function") try: word_count = lowermodule.word_count(myfile) with open('wordcountarchive.csv', 'a') as file: row = str(myfile) + ',' + str(word_count) file.write(row + '\n') except: logger.warning("could not write file %s to destination", myfile) finally: logger.debug("the function is done for the file %s", myfile)Si nous exécutons uppermodule.py sur un fichier accessible (monfichier.txt) suivi d’un fichier inaccessible (inexistantfichier.txt), le module de journalisation générera la sortie suivante :
2019-03-27 21:16:41,200 __main__ INFO:starting the function2019-03-27 21:16:41,200 lowermodule INFO:this file has 44 words2019-03-27 21:16:41,201 __main__ DEBUG:the function is done for the file myfile.txt2019-03-27 21:16:41,201 __main__ INFO:starting the function2019-03-27 21:16:41,202 lowermodule ERROR: No such file or directory: 'nonexistentfile.txt'2019-03-27 21:16:41,202 __main__ DEBUG:the function is done for the file nonexistentfile.txtLe nom du logger est inclus juste après l’horodatage, afin que vous puissiez voir exactement quel module a généré chaque message. Si vous ne définissez pas le logger avec getLogger(), chaque nom de logger apparaîtra sous la forme root, ce qui rendra difficile de discerner quels messages ont été journalisés par le uppermodule par opposition au lowermodule. Les messages qui ont été journalisés à partir de uppermodule.py listent le module __main__ comme nom du logger, parce que uppermodule.py a été exécuté comme script de premier niveau.
Bien que nous capturions maintenant automatiquement le nom du logger dans le cadre du format du journal, ces deux loggers sont configurés avec la même ligne basicConfig(). Dans la section suivante, nous vous montrerons comment rationaliser votre configuration de journalisation en utilisant fileConfig() pour appliquer la configuration de journalisation sur plusieurs enregistreurs.
Utiliser fileConfig() pour sortir les journaux vers plusieurs destinations
Bien que basicConfig() permette de démarrer rapidement et facilement avec la journalisation, l’utilisation d’une configuration basée sur les fichiers (fileConfig()) ou sur les dictionnaires (dictConfig()) vous permet de mettre en œuvre davantage d’options de formatage et de routage personnalisées pour chaque enregistreur de votre application, et d’acheminer les journaux vers plusieurs destinations. C’est également le modèle que des frameworks populaires comme Django et Flask utilisent pour configurer la journalisation des applications. Dans cette section, nous allons examiner de plus près la configuration de la journalisation basée sur les fichiers. Un fichier de configuration de journalisation doit contenir trois sections :
- : les noms des loggers que vous allez configurer.
- : le ou les handlers que ces
loggersdoivent utiliser (par ex,consoleHandlerfileHandler). - : le(s) format(s) que vous souhaitez que chaque logger suive lors de la génération d’un journal.
Chaque section doit inclure une liste séparée par des virgules d’une ou plusieurs clés : keys=handler1,handler2,. Les clés déterminent les noms des autres sections que vous devrez configurer, sous la forme , où le nom de la section est logger, handler ou formatter. Un exemple de fichier de configuration de journalisation (logging.ini) est présenté ci-dessous.
keys=rootkeys=fileHandlerkeys=simpleFormatterlevel=DEBUGhandlers=fileHandlerclass=FileHandlerlevel=DEBUGformatter=simpleFormatterargs=("/path/to/log/file.log",)format=%(asctime)s %(name)s - %(levelname)s:%(message)sLa documentation de journalisation de Python recommande de n’attacher chaque handler qu’à un seul logger et de compter sur la propagation pour appliquer les handlers aux loggers enfants appropriés. Cela signifie que si vous avez une configuration de journalisation par défaut que vous voulez que tous vos loggers reprennent, vous devez l’ajouter à un logger parent (tel que le logger racine), plutôt que de l’appliquer à chaque logger de niveau inférieur. Consultez la documentation pour plus de détails sur la propagation. Dans cet exemple, nous avons configuré un logger racine et l’avons laissé se propager aux deux modules de notre application (lowermodule et uppermodule). Les deux enregistreurs produiront des journaux DEBUG et des journaux de priorité supérieure, dans le format spécifié (formatter_simpleFormatter), et les ajouteront à un fichier journal (file.log). Cela supprime la nécessité d’inclure logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s') dans les deux modules.
A la place, une fois que vous avez créé ce fichier de configuration de journalisation, vous pouvez ajouter logging.config.fileConfig() à votre code comme suit :
import logging.configlogging.config.fileConfig('/path/to/logging.ini', disable_existing_loggers=False)logger = logging.getLogger(__name__)Assurez-vous de import logging.config afin d’avoir accès à la fonction fileConfig(). Dans cet exemple, disable_existing_loggers est défini sur False, ce qui indique que le module de journalisation ne doit pas désactiver les enregistreurs non root préexistants. Ce paramètre est défini par défaut sur True, ce qui désactivera tous les loggers non-root qui existaient avant fileConfig(), à moins que vous ne les configuriez par la suite.
Votre application devrait maintenant commencer la journalisation en fonction de la configuration que vous avez établie dans votre fichier logging.ini. Vous avez également la possibilité de configurer la journalisation sous la forme d’un dictionnaire Python (via dictConfig()), plutôt que dans un fichier. Consultez la documentation pour plus de détails sur l’utilisation de fileConfig() et dictConfig().
Gestion des exceptions Python et tracebacks
La journalisation du traceback dans vos journaux d’exceptions peut être très utile pour le dépannage des problèmes. Comme nous l’avons vu précédemment, logging.error() n’inclut aucune information de traceback par défaut – elle enregistrera simplement l’exception comme une erreur, sans fournir de contexte supplémentaire. Pour s’assurer que logging.error() capture le traceback, définissez le paramètre sys.exc_infoTrue. Pour illustrer, essayons de consigner une exception avec et sans exc_info:
# lowermodule.pylogging.config.fileConfig('/path/to/logging.ini', disable_existing_loggers=False)logger = logging.getLogger(__name__)def word_count(myfile): try: # count the number of words in a file, myfile, and log the result except OSError as e: logger.error(e) logger.error(e, exc_info=True)Si vous exécutez le code avec un fichier inaccessible (ex, nonexistentfile.txt) comme entrée, il générera la sortie suivante:
2019-03-27 21:01:58,191 lowermodule - ERROR: No such file or directory: 'nonexistentfile.txt'2019-03-27 21:01:58,191 lowermodule - ERROR: No such file or directory: 'nonexistentfile.txt'Traceback (most recent call last): File "/home/emily/logstest/lowermodule.py", line 14, in word_count with open(myfile, 'r') as f:FileNotFoundError: No such file or directory: 'nonexistentfile.txt'La première ligne, enregistrée par logger.error(), ne fournit pas beaucoup de contexte au-delà du message d’erreur (« No such file or directory »). La deuxième ligne montre comment l’ajout de exc_info=Truelogger.error() permet de capturer le type d’exception (FileNotFoundError) et le traceback, qui comprend des informations sur la fonction et le numéro de ligne où cette exception a été levée.
Alternativement, vous pouvez également utiliser logger.exception() pour consigner l’exception à partir d’un gestionnaire d’exception (comme dans une clause except). Cela capture automatiquement les mêmes informations de traçage présentées ci-dessus et définit ERROR comme niveau de priorité du journal, sans que vous ayez à définir explicitement exc_infoTrue. Quelle que soit la méthode que vous utilisez pour capturer le traceback, le fait de disposer des informations complètes sur les exceptions dans vos journaux est essentiel pour surveiller et dépanner les performances de vos applications.
Capturer les exceptions non gérées
Vous ne serez jamais en mesure d’anticiper et de traiter toutes les exceptions possibles, mais vous pouvez vous assurer de consigner les exceptions non gérées afin de pouvoir les étudier ultérieurement. Une exception non gérée se produit en dehors d’un bloc try...except, ou lorsque vous n’incluez pas le bon type d’exception dans votre déclaration except. Par exemple, si votre application rencontre une exception TypeError, et que votre clause except ne gère qu’une NameError, elle sera transmise à toutes les autres clauses try jusqu’à ce qu’elle rencontre le bon type d’exception.
Si ce n’est pas le cas, elle devient une exception non gérée, auquel cas l’interprète invoquera sys.excepthook(), avec trois arguments : la classe d’exception, l’instance d’exception et le traceback. Ces informations apparaissent généralement dans sys.stderr mais si vous avez configuré votre logger pour qu’il sorte dans un fichier, les informations de traceback n’y seront pas enregistrées.
Vous pouvez utiliser la bibliothèque standard de Python traceback pour formater le traceback et l’inclure dans le message du log. Revoyons notre fonction word_count() pour qu’elle tente d’écrire le nombre de mots dans le fichier. Comme nous avons fourni le mauvais nombre d’arguments dans la fonction write(), elle lèvera une exception :
# lowermodule.pyimport logging.configimport tracebacklogging.config.fileConfig('logging.ini', disable_existing_loggers=False)logger = logging.getLogger(__name__)def word_count(myfile): try: # count the number of words in a file, myfile, and log the result with open(myfile, 'r+') as f: file_data = f.read() words = file_data.split(" ") final_word_count = len(words) logger.info("this file has %d words", final_word_count) f.write("this file has %d words", final_word_count) return final_word_count except OSError as e: logger.error(e, exc_info=True) except: logger.error("uncaught exception: %s", traceback.format_exc()) return Falseif __name__ == '__main__': word_count('myfile.txt')L’exécution de ce code rencontrera une TypeError exception qui n’est pas traitée dans la logique try-except. Cependant, puisque nous avons ajouté le code traceback, elle sera enregistrée, grâce au code de traçage inclus dans la deuxième clause except :
# exception doesn't get handled but still gets logged, thanks to our traceback code2019-03-28 15:22:31,121 lowermodule - ERROR:uncaught exception: Traceback (most recent call last): File "/home/emily/logstest/lowermodule.py", line 23, in word_count f.write("this file has %d words", final_word_count)TypeError: write() takes exactly one argument (2 given)La journalisation du traceback complet au sein de chaque exception gérée et non gérée offre une visibilité critique sur les erreurs lorsqu’elles se produisent en temps réel, afin que vous puissiez enquêter sur le moment et la raison de leur apparition. Bien que les exceptions à plusieurs lignes soient faciles à lire, si vous regroupez vos journaux avec un service de journalisation externe, vous voudrez convertir vos journaux en JSON pour vous assurer que vos journaux à plusieurs lignes sont analysés correctement. Ensuite, nous vous montrerons comment utiliser une bibliothèque comme python-json-logger pour journaliser au format JSON.
Unifier tous vos journaux Python
Jusqu’à présent, nous vous avons montré comment configurer la bibliothèque de journalisation intégrée de Python, personnaliser le format et le niveau de gravité de vos journaux, et capturer des informations utiles comme le nom du logger et les traces des exceptions. Nous avons également utilisé la configuration basée sur les fichiers pour mettre en œuvre des options plus dynamiques de formatage et de routage des journaux. Nous pouvons maintenant nous intéresser à l’interprétation et à l’analyse de toutes les données que nous collectons. Dans cette section, nous vous montrerons comment formater les logs en JSON, ajouter des attributs personnalisés, et centraliser et analyser ces données avec une solution de gestion des logs pour obtenir une visibilité plus profonde sur les performances des applications, les erreurs, et plus encore.
Stratez votre collecte et votre analyse des logs Python avec Datadog.
Log au format JSON
Alors que vos systèmes génèrent plus de logs au fil du temps, il peut rapidement devenir difficile de localiser les logs qui peuvent vous aider à résoudre des problèmes spécifiques – surtout lorsque ces logs sont distribués sur plusieurs serveurs, services et fichiers. Si vous centralisez vos journaux avec une solution de gestion des journaux, vous saurez toujours où chercher chaque fois que vous aurez besoin de rechercher et d’analyser vos journaux, plutôt que de vous connecter manuellement à chaque serveur d’application.
La journalisation en JSON est une meilleure pratique lorsque vous centralisez vos journaux avec un service de gestion des journaux, car les machines peuvent facilement analyser ce format standard et structuré. Le format JSON est également facilement personnalisable pour inclure tous les attributs que vous décidez d’ajouter à chaque format de journal, de sorte que vous n’aurez pas besoin de mettre à jour vos pipelines de traitement des journaux chaque fois que vous ajoutez ou supprimez un attribut de votre format de journal.
La communauté Python a développé diverses bibliothèques qui peuvent vous aider à convertir vos journaux au format JSON. Pour cet exemple, nous utiliserons python-json-logger pour convertir les enregistrements de logs en JSON.
D’abord, installez-le dans votre environnement :
pip install python-json-loggerMettez maintenant à jour le fichier de configuration de journalisation (par ex, logging.ini) pour personnaliser un formateur existant ou ajouter un nouveau formateur qui formatera les journaux en JSON ( dans l’exemple ci-dessous). Le formateur JSON doit utiliser la classe pythonjsonlogger.jsonlogger.JsonFormatter. Dans la clé format du formateur, vous pouvez spécifier les attributs que vous souhaitez inclure dans l’objet JSON de chaque enregistrement de journal :
keys=root,lowermodulekeys=consoleHandler,fileHandlerkeys=simpleFormatter,jsonlevel=DEBUGhandlers=consoleHandlerlevel=DEBUGhandlers=fileHandlerqualname=lowermoduleclass=StreamHandlerlevel=DEBUGformatter=simpleFormatterargs=(sys.stdout,)class=FileHandlerlevel=DEBUGformatter=jsonargs=("/home/emily/myapp.log",)class=pythonjsonlogger.jsonlogger.JsonFormatterformat=%(asctime)s %(name)s %(levelname)s %(message)sformat=%(asctime)s %(name)s - %(levelname)s:%(message)sLes journaux qui sont envoyés à la console (avec la consoleHandler) suivront toujours le format simpleFormatter pour la lisibilité, mais les journaux produits par le logger lowermodule seront écrits dans le fichier myapp.log file au format JSON.
Une fois que vous avez inclus la classe pythonjsonlogger.jsonlogger.JsonFormatter dans votre fichier de configuration de journalisation, la fonction fileConfig() devrait pouvoir créer la JsonFormatter tant que vous exécutez le code depuis un environnement où il peut importer pythonjsonlogger.
Si vous n’utilisez pas la configuration par fichier, vous devrez importer la bibliothèque python-json-logger dans le code de votre application, et définir un gestionnaire et un formateur, comme décrit dans la documentation :
from pythonjsonlogger import jsonloggerlogger = logging.getLogger()logHandler = logging.StreamHandler()formatter = jsonlogger.JsonFormatter()logHandler.setFormatter(formatter)logger.addHandler(logHandler)Pour voir pourquoi le format JSON est préférable, en particulier lorsqu’il s’agit d’enregistrements de journaux plus complexes ou détaillés, revenons à l’exemple du traceback d’exception de plusieurs lignes que nous avons enregistré précédemment. Il ressemblait à quelque chose comme ceci :
2019-03-27 21:01:58,191 lowermodule - ERROR: No such file or directory: 'nonexistentfile.txt'Traceback (most recent call last): File "/home/emily/logstest/lowermodule.py", line 14, in word_count with open(myfile, 'r') as f:FileNotFoundError: No such file or directory: 'nonexistentfile.txt'Bien que ce journal de traçage des exceptions soit facile à lire dans un fichier ou dans la console, s’il est traité par une plateforme de gestion des journaux, chaque ligne peut s’afficher comme un journal distinct (à moins que vous ne configuriez des règles d’agrégation multilignes), ce qui peut rendre difficile la reconstitution exacte de ce qui s’est passé.
Maintenant que nous enregistrons cette remontée d’exception en JSON, l’application va générer un seul journal qui ressemble à ceci :
{"asctime": "2019-03-28 17:44:40,202", "name": "lowermodule", "levelname": "ERROR", "message": " No such file or directory: 'nonexistentfile.txt'", "exc_info": "Traceback (most recent call last):\n File \"/home/emily/logstest/lowermodule.py\", line 19, in word_count\n with open(myfile, 'r') as f:\nFileNotFoundError: No such file or directory: 'nonexistentfile.txt'"}Un service de journalisation peut facilement interpréter ce journal JSON et afficher les informations de remontée complètes (y compris l’attribut exc_info) dans un format facile à lire :
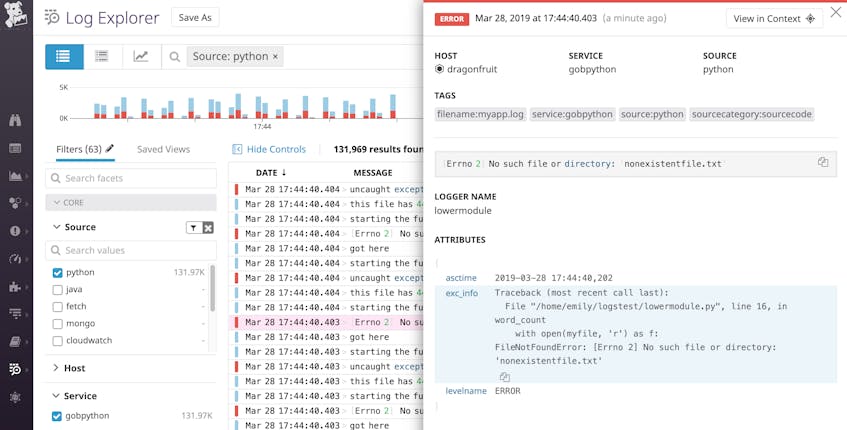
Ajouter des attributs personnalisés à vos journaux JSON
Un autre avantage de la journalisation en JSON est que vous pouvez ajouter des attributs qu’un service externe de gestion des journaux peut analyser automatiquement. Plus tôt, nous avons configuré la format pour inclure des attributs standard comme %(asctime)s%(name)s%(levelname)s, et %(message)s. Vous pouvez également enregistrer des attributs personnalisés en utilisant le champ « extra » de python-json-logs. Ci-dessous, nous avons créé un nouvel attribut qui suit la durée de cette opération :
# lowermodule.pyimport logging.configimport tracebackimport timedef word_count(myfile): logger = logging.getLogger(__name__) logging.fileConfig('logging.ini', disable_existing_loggers=False) try: starttime = time.time() with open(myfile, 'r') as f: file_data = f.read() words = file_data.split(" ") final_word_count = len(words) endtime = time.time() duration = endtime - starttime logger.info("this file has %d words", final_word_count, extra={"run_duration":duration}) return final_word_count except OSError as e: Cet attribut personnalisé, run_duration, mesure la durée de l’opération en secondes :
{"asctime": "2019-03-28 18:13:05,061", "name": "lowermodule", "levelname": "INFO", "message": "this file has 44 words", "run_duration": 6.389617919921875e-05}Dans une solution de gestion des journaux, les attributs de ce journal JSON seraient analysés en quelque chose qui ressemble à ce qui suit :
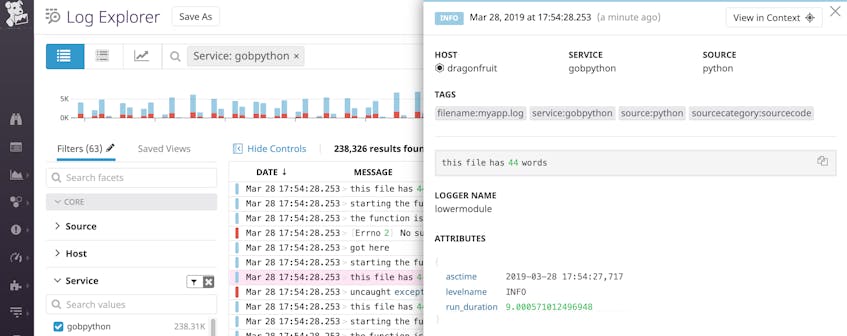
Si vous utilisez une plateforme de surveillance des journaux, vous pouvez établir un graphique et une alerte sur la run_duration de votre application au fil du temps. Vous pouvez également exporter ce graphique vers un tableau de bord si vous souhaitez le visualiser côte à côte avec les performances de l’application ou les métriques d’infrastructure.
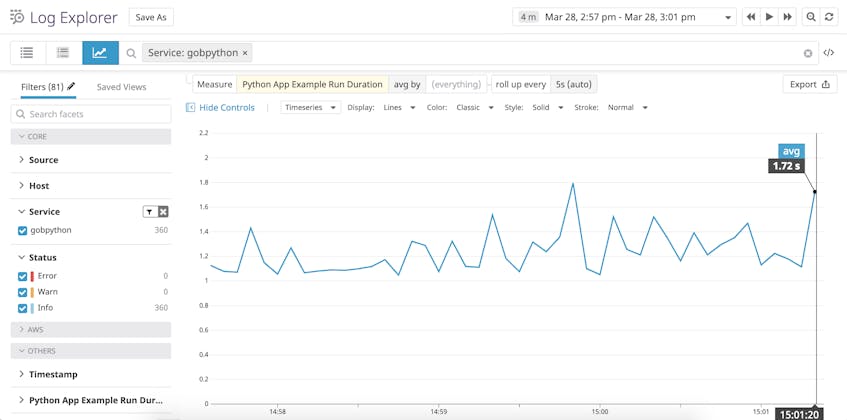
Que vous utilisiez python-json-logger ou une autre bibliothèque pour formater vos logs Python en JSON, il est facile de personnaliser vos journaux pour inclure des informations que vous pouvez analyser avec une plateforme externe de gestion des journaux.
Corréler les logs avec d’autres sources de données de surveillance
Une fois que vous centralisez vos logs Python avec un service de surveillance, vous pouvez commencer à les explorer aux côtés des traces de requêtes distribuées et des métriques d’infrastructure pour obtenir une visibilité plus profonde de vos applications. Un service comme Datadog peut connecter les journaux avec les métriques et les données de surveillance des performances des applications pour vous aider à avoir une vue d’ensemble.
Par exemple, si vous mettez à jour votre format de journal pour inclure les attributs dd.trace_id et dd.span_id, Datadog mettra automatiquement en corrélation les journaux et les traces de chaque requête individuelle. Cela signifie que lorsque vous visualisez une trace, vous pouvez simplement cliquer sur l’onglet « Logs » de la vue de la trace pour voir tous les journaux générés pendant cette requête spécifique, comme indiqué ci-dessous.
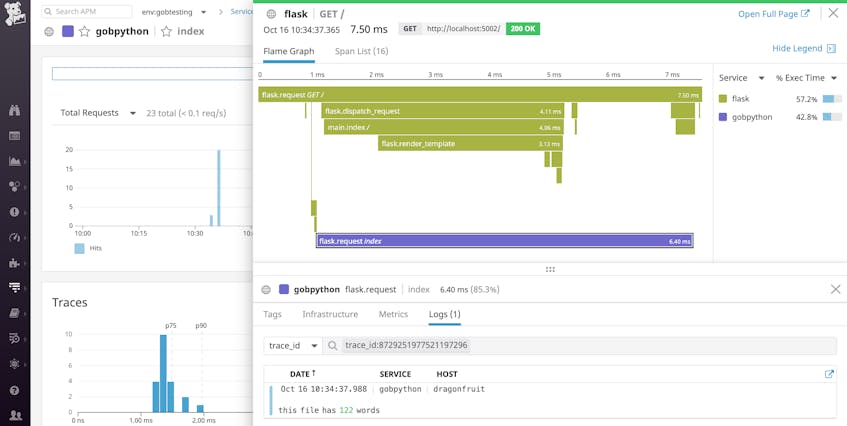
Vous pouvez également naviguer dans l’autre sens – d’un journal à la trace de la requête qui a généré le journal – si vous devez enquêter sur un problème spécifique. Consultez notre documentation pour plus de détails sur la corrélation automatique des logs et des traces Python pour un dépannage plus rapide.
Centraliser et analyser vos logs Python
Dans ce post, nous avons parcouru quelques bonnes pratiques pour configurer la bibliothèque de logs standard de Python afin de générer des logs riches en contexte, de capturer des traces d’exception et de router les logs vers les destinations appropriées. Nous avons également vu comment vous pouvez centraliser, analyser et analyser vos journaux au format JSON avec une plateforme de gestion des journaux lorsque vous avez besoin de dépanner ou de déboguer des problèmes. Si vous souhaitez surveiller les logs de vos applications Python avec Datadog, inscrivez-vous à un essai gratuit.